你好,我是彭旭。
从这节课开始,我们要积累一部分数据库的基础知识。今天我们主要聚焦在列式存储和行式存储的区别上,再给你介绍一个被多个数据库引擎支持的、最流行的列式数据存储格式。
在大数据时代,列式存储出现的频率很高,讨论列式存储优势的文章汗牛充栋,这些信息给人一种“列式存储难道是最优秀的数据库存储格式”的感觉,实际上这可能是一个“可得性启发”。比如如果你经常听到飞机事故,你可能会觉得飞机是最危险的交通工具一样,而实际上飞机是一个相对更安全的交通工具。
那行式存储真的会被列式存储替代吗?我们先来简单对比一下它们之间的不同。
行列存储对比
顾名思义,行式存储其实就是将数据库的一行数据物理上也存储在一起,列式存储则是按照列将数据物理上存储在一起。
你看下面这张图,R1C1代表第1行数据的第1列,R3C1代表第3行的第1列。
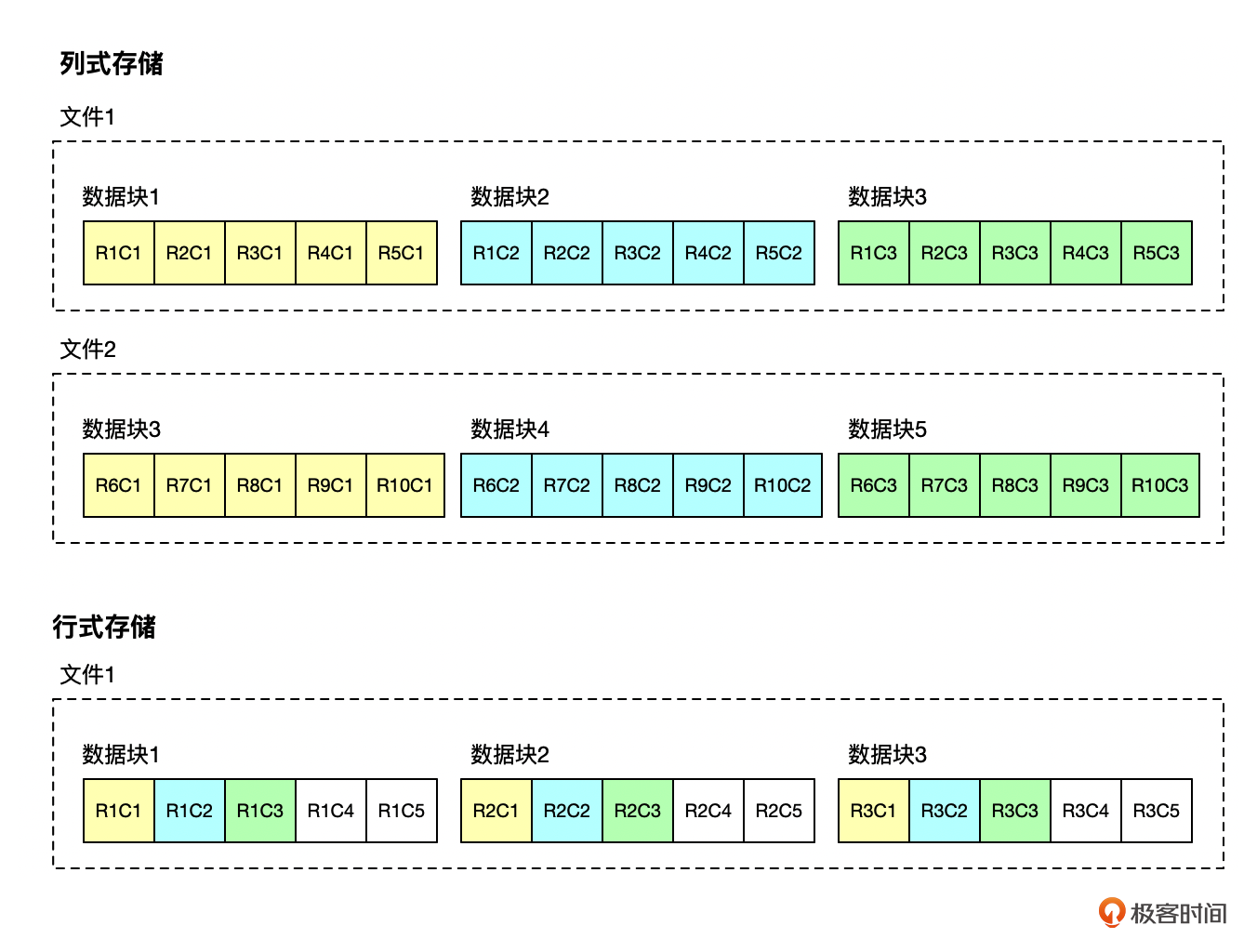
我们可以观察出两点。
- 在列式存储下,列C1的数据在磁盘上聚簇地存储在数据块(或者页),但是一列可以由多个数据块或者数据文件存储。
- 在行式存储下,行R1的数据在磁盘上聚簇地存储在数据块上。
其实行式存储与列式存储的发展,与其对应的不同类型的数据库发展息息相关。
我们先来看一个例子。假设一个订单表有40个字段,包括订单编号、订单金额、订单状态、商品名称、会员信息等。
在OLTP(联机事务处理)场景下,通常我们的需求是根据订单编号来更新订单状态,或者通过订单编号查询订单的细节信息(金额、商品名称等)来处理售后需求等。
在这些场景里,都需要用订单编号来把订单的详情,也就是这40个字段都查询、展示出来,更新某些字段后,再整行存储。
如果使用行式存储,这40个字段就会存储在磁盘的同一个数据块里,读取数据的时候能够一次性顺序读取出来。反之,如果使用列式存储,一行数据的这40个字段可能分布在40个数据块里,我们要遍历这40个数据块才能将这个订单的详情“凑”完整,是不是很恼火?
所以,OLTP场景下,我们一般使用行式存储,这就是传统关系型数据库的做法。
好,总结一下。虽然不是说关系型数据库就一定要用行式存储,但是关系型数据库的一些特性就决定了使用行式存储是一个较优的选择。
- 在OLTP场景,数据一般以行的形式进行处理与查询,一行数据通常被一起插入、一起查询、一起更新,这样,使用行式存储就能够以最少的磁盘读写代价处理一行业务数据的读写。
- 关系型数据库需要支持事务,一行数据或者多行数据需要能够一起持久化成功或者一起失败,按行存储能够简化读写的I/O,提升性能。
这里提一句,MySQL这种关系型数据库数据的写入并不是直接发生在磁盘上的。它的更新操作首先是将数据写入内存,并同时生成一条Redo日志记录。这种日志记录机制保证了数据的持久性和可恢复性,用于故障时重做来恢复数据。当达到特定的刷新阈值时,如事务提交或日志缓冲区满,内存中的数据才会被写入磁盘。
因此,即使在事务的上下文中,数据的写入或更新也不是立即映射到磁盘上的行式存储结构中的。这个过程是由InnoDB存储引擎内部的缓冲和日志刷新机制决定的,能够有效地提高事务处理的性能。
那到了OLAP(联机分析处理)场景下呢?同样的订单表,我们关注的是销售额怎么样,哪些商品品类卖得比较好等。这时候通常是按日期统计一下订单金额字段的总和。
如果使用列式存储,同一列的值存储在一起,假设某天的销售额有10000个订单需要统计,那么可能5000个订单的订单金额列存储在一起,订单金额这一列就只占用2个数据块,这样只需要扫描这2个数据块,将扫描到的数据直接累加,就得到了销售额。
反之,如果使用行式存储,一个数据块即使能够存储1000行数据,那么也要扫描10000/1000=10个数据块,扫描完全部数据,从数据行中挑出订单金额的列,才能累加得到订单金额的汇总。
所以OLAP场景下,我们一般使用列式存储,这也是分析型数据库的做法。
好,咱们用更专业的话总结一下。列式存储适用于分析型数据库,有两点原因。
- 分析型数据库一般都是批量写入数据,同一列数据一起批量写入,这一列的数据类型相同,所以具备更高的压缩率,可以加快数据的读写速度。
- OLAP场景一般需要扫描大量数据行,但是基本是对一列或者多列进行统计分析、聚合等,列式存储可以只读取所需的列,从而避免加载整个行的数据,这大大减少了I/O操作,提高了查询效率。
用比喻来说的话,OLTP像单个业务执行者,快速的处理单个事务以及有限条数据,确保业务顺畅进行;而OLAP就像是战略分析家,深入剖析数据,为决策提供支持。
回到开头,其实列式存储被提及越来越多主要还是大数据技术的发展,数据已经是企业数字化决策与战略方向制定的一个可靠参考。而这些决策的数据支撑都是通过采集企业内外部各个系统的数据,然后汇聚到基于列式存储的数据仓库,最后通过多维分析挖掘出来的。所以才会给你一种列式存储马上要取代行式存储的错觉。
话说回来,分布式时代的数据库,基本都使用的是列式存储,比如HBase、Cassandra、ClickHouse、StarRocks等。这里提一下其实HBase是一个宽列存储,基本跟行式存储差不多了。
我给你提供一个表格,是咱们后面要学习的HBase、StarRocks和ClickHouse的存储模式和适用场景。

有一个细节需要注意,表格里虽然写着HBase是宽列存储模式,但基本上还是一行数据存储在一起,所以能够在高并发、实时要求高的OLTP场景下使用,其他两个列式存储的数据库则都适用于数据分析的场景,不过在大量数据分析与实时性能上做了一些平衡取舍。
Parquet:一种存储格式
列式存储作为我们接下来要介绍的几种类型数据库的基石,很值得详细说说。尤其它支持的很多种存储格式,有Apache Parquet、Apache ORC等等。
这节课我们先聊聊Apache Parquet。之所以选它,就是因为它是列式存储中最流行的格式,主流数据库基本都支持,很多分析工具也能直接分析Parquet文件,工作中需要迁移数据、分析数据、实时计算等等,大多都会和这种格式打交道。
我们将要介绍的几个数据库也都与Parquet有千丝万缕的关联,比如HBase数据可以导出为Parquet,然后用Spark等工具来进行批量分析。ClickHouse与StarRocks都支持直接读取与写入Parquet数据。
实际上,Parquet不单单是一个数据库的存储格式,它同样能够用于大规模的数据分析与处理,比如与Spark、Flink等集成,也支持直接用Python、Java等语言来读写,甚至你可以将自己的数据写成一个Parquet文件,然后使用支持Parquet格式的引擎来分析你的数据。
那Parquet到底为什么能被广泛接受并流行起来呢?因为除了依托于Hadoop生态体系的支持外,Parquet也满足了一个优秀的存储格式设计各个方面的要求。
- 支持多种高效的编码与压缩算法,在减少存储空间的同时,仍然能够保持良好的读取性能。
- 兼容性方面不局限于Hadoop生态,不局限于语言,提供了跨平台的数据交换能力。
- 提供高性能支持,比如使用分区、索引、布隆过滤器等来支持过滤掉不需要扫描的数据等。
我们先来看一下Parquet文件格式长什么样子。
1 | 4-byte magic number "PAR1" |
简单来说,这里描述了一个N列的表,每一列又被分成M个行组(Row Group),也就是上面的“Chunk 1到M”。行组可以看作是Parquet文件内部的分区,存储着一定数量的数据行。文件内容中,列块旁边还存储着一个列的元数据,列的元数据包含了列的数据类型、编码压缩方式、数据的起始位置、统计值等。
再下面的位置,还有一个File Metadata,是文件的元数据。文件元数据用来描述整个文件的版本信息、schema、行组信息等。文件的元数据的写入是在数据写入之后完成的。这样,一旦数据写入完成,对应的元数据也就确定了。这种方式可以一次性将数据和元数据一起写入文件,避免了需要进行更新的情况。数据读取的时候也能通过文件元数据快速找到需要读取的列块(Column Chunk)。
当然你也不需要去记住Parquet文件的详细格式,只需了解文件里面存储了哪些数据以及这些数据可以用来干什么就好了。
构建你自己的Parquet文件
前面还提到Parquet具备很好的兼容性,不局限于语言,所以,我们可以通过很多方式来构建自己的Parquet数据文件。比如使用Python提供的PyArrow库,就可以快速地将你的数据存储为Parquet文件。
在大规模的分布式数据系统中,同时处理大数据量的实时随机存取与批量分析是一个很复杂的问题,因为没有一个存储引擎能够同时精通实时随机存取与批量分析,所以诞生了一个叫做Lambda的架构。
Lambda的核心思想是通过分层与管道来构建一个混合架构。比如采用HBase来满足实时随机存取的需求,然后将HBase的数据导出来,转成Parquet文件,接着将Parquet文件导入到像HDFS之类的文件存储中,最后通过Spark、Impala之类的分析引擎来查询数据,满足批量分析的需求。
当然,Lambda架构实际上更复杂,这里我们用一个简单的例子来模拟写入数据生产Parquet文件,然后使用PySpark来分析这个文件。
1 | import pyarrow as pa |
可以看到这段代码用一个DataFrame声明了一个表数据,然后基于表数据转化成一个pa的表,最后将表使用PyArrow引擎写入了ls1_output.parquet文件,当然实际上我们还有很多事情可以处理,比如设置写入的Parquet文件列的压缩方式、编码方式等。这些会在后面的课程陆续介绍。
注意,输出的Parquet文件是一个二进制文件,无法直接查看,但是可以通过ParquetViewer这类工具查看或者让程序读取。
读取分析你的Parquet文件
Parquet文件的读取分析也很简单,常用的大数据分析引擎基本都能够支持,比如Apache Spark、Apache Drill、Apache Impala、Presto等。
那怎么使用Spark读取我们构建的Parquet文件呢?
看下面的代码,这个就是从刚刚我们写入的Parquet文件读取数据,实现的按部门汇总薪资的统计分析。
1 | from pyspark.sql import SparkSession |
输出结果如图所示。
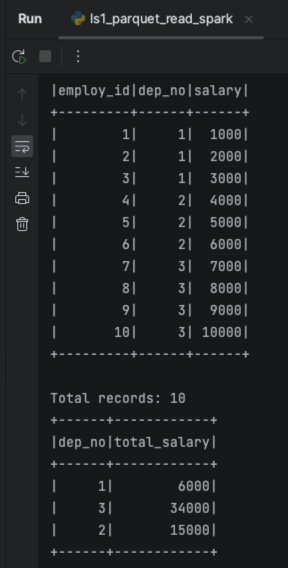
好了,到这里相信你对列式存储已经有了一定的了解,也知道了如何基于自己的数据构建Parquet列式存储文件,然后使用工具进行统计分析。
小结
这节课我们介绍了两个重点内容,行式存储与列式存储的不同,以及列式存储格式Parquet。
行式存储适用于OLTP系统针对单行读写较多的场景,而列式存储则适合在OLAP场景下,批量导入,多次查询。
咱们的课程会专注于列式存储数据库,所以,我也给你介绍了HBase、ClickHouse、StarRocks这几种数据库的存储模式。其实,一般高效的数据库,都会自行定义自有的一个数据存储格式,但是也都会提供对诸如Parquet之类格式文件的支持与集成。也正是因为如此,才会显得Parquet如此重要。
Parquet作为大数据时代下最流行的列式存储格式,很多分布式数据库都支持将Parquet文件作为外部表,比如StarRocks、Hive等,也有很多数据查询引擎与计算框架如Spark、Presto、MapReduce等都支持直接读取分析Parquet文件。
我还举了一个在Lambda场景下使用Parquet作为数据管道传递格式的简单示例,将一个员工表的数据通过PyArrow写成了一个Parquet文件,用Spark做了统计分析。相信你已经知道了如何使用Parquet来存储、分析数据了。
下节课,我们仍然会介绍存储相关的内容,看看被大数据存储引擎广泛使用的数据结构LSM树是怎样优化数据库的读写性能的。
思考题
你觉得数据库存储模式的发展趋势会是怎样?行式存储还是列式存储优先?或者说混合模式优先?
欢迎在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。欢迎你加入我们的读者交流群,我们下节课见!