# 导入一个搜索UID的工具 from tools.search_tool import get_UID
# 导入所需的库 from langchain.prompts import PromptTemplate from langchain.chat_models import ChatOpenAI from langchain.agents import initialize_agent, Tool from langchain.agents import AgentType
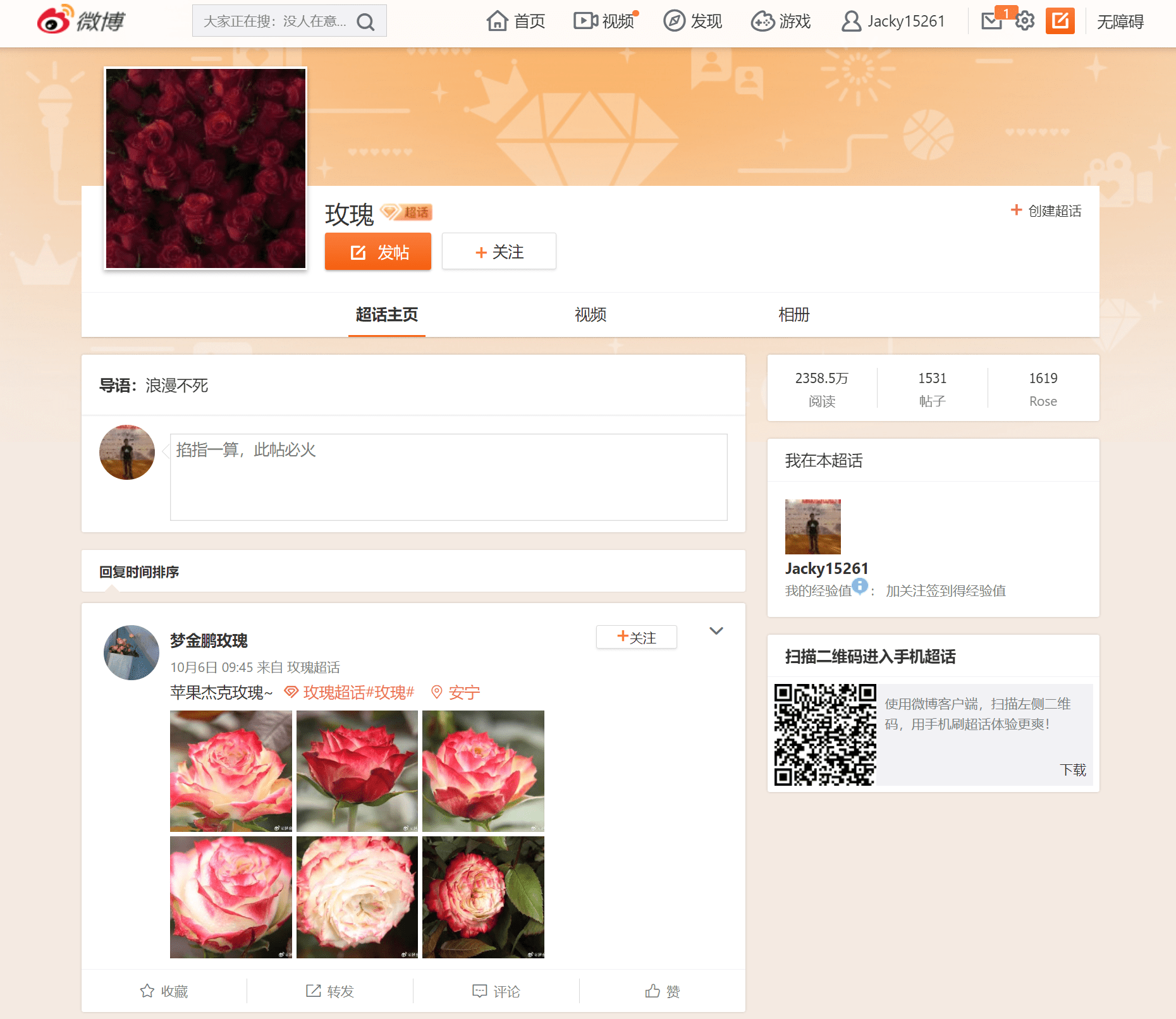
# 寻找UID的模板 template = """given the {flower} I want you to get a related 微博 UID. Your answer should contain only a UID. The URL always starts with https://weibo.com/u/ for example, if https://weibo.com/u/1669879400 is her 微博, then 1669879400 is her UID This is only the example don't give me this, but the actual UID""" # 完整的提示模板 prompt_template = PromptTemplate( input_variables=["flower"], template=template )
# 代理的工具 tools = [ Tool( name="Crawl Google for 微博 page", func=get_UID, description="useful for when you need get the 微博 UID", ) ]
# 寻找UID的模板 template = """given the {flower} I want you to get a related 微博 UID. Your answer should contain only a UID. The URL always starts with https://weibo.com/u/ for example, if https://weibo.com/u/1669879400 is her 微博, then 1669879400 is her UID This is only the example don't give me this, but the actual UID"""
定制的 SerpAPI:getUID
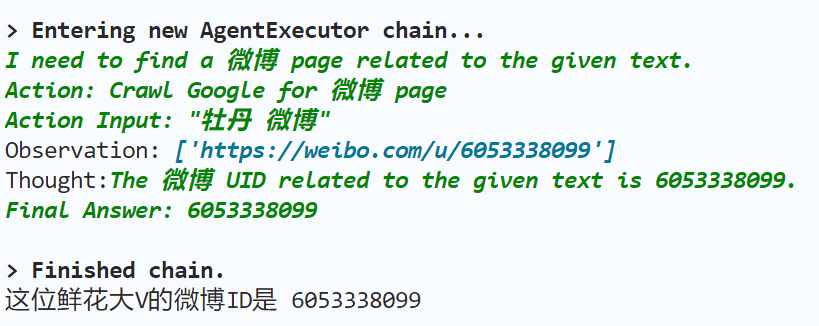
上面的程序只是调用了代理,但是没有给出具体的工具实现。现在我们来继续实现搜索大V的UID的功能。
1 2
# 导入一个搜索UID的工具 from tools.search_tool import get_UID
# 导入SerpAPIWrapper from langchain.utilities import SerpAPIWrapper
# 重新定制SerpAPIWrapper,重构_process_response,返回URL class CustomSerpAPIWrapper(SerpAPIWrapper): def __init__(self): super(CustomSerpAPIWrapper, self).__init__()
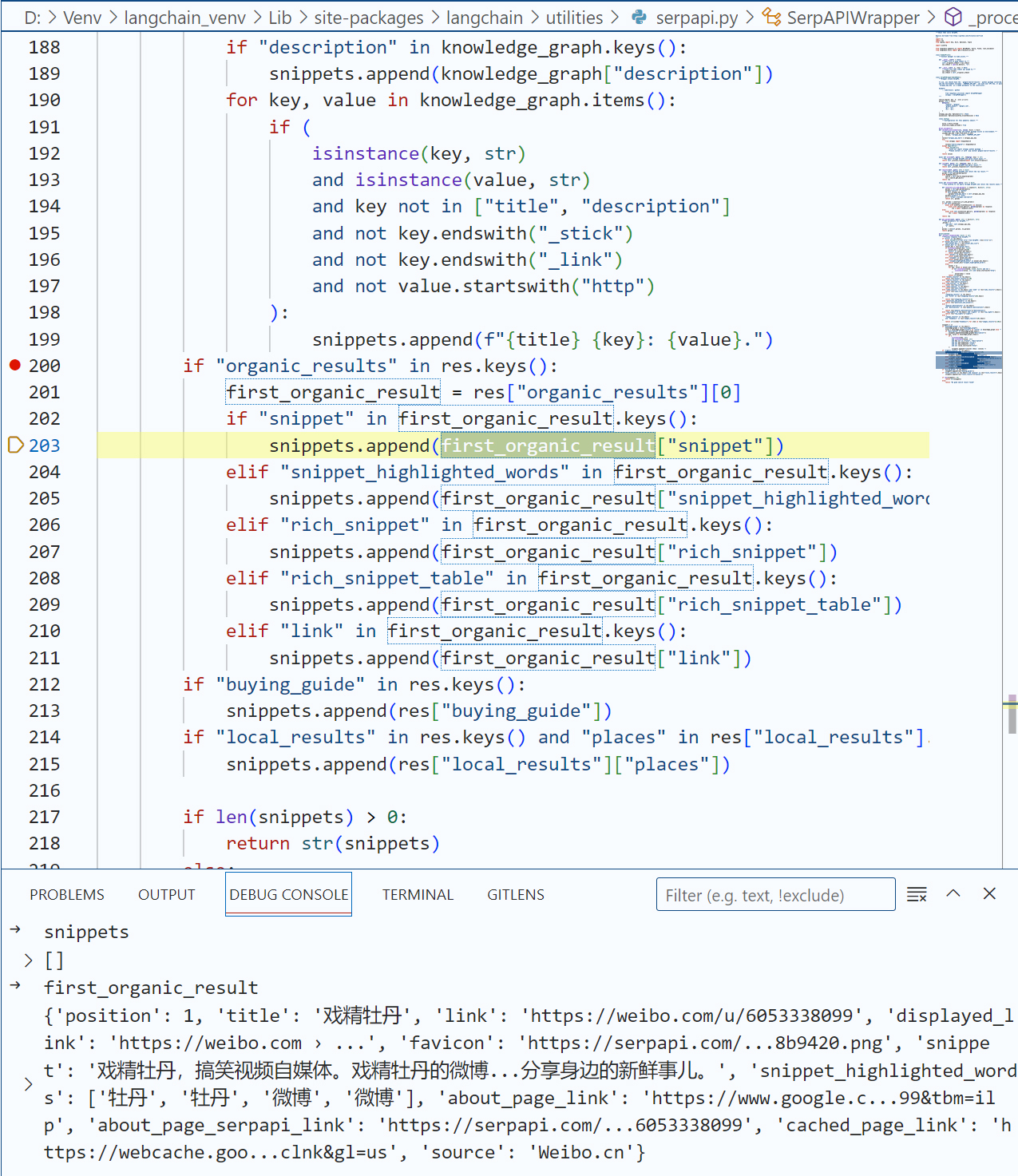
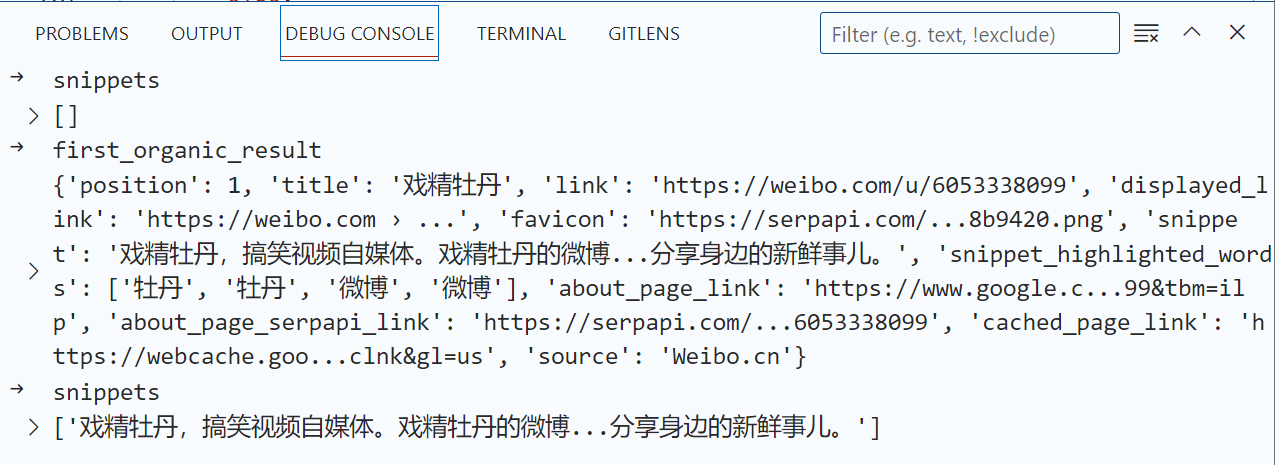
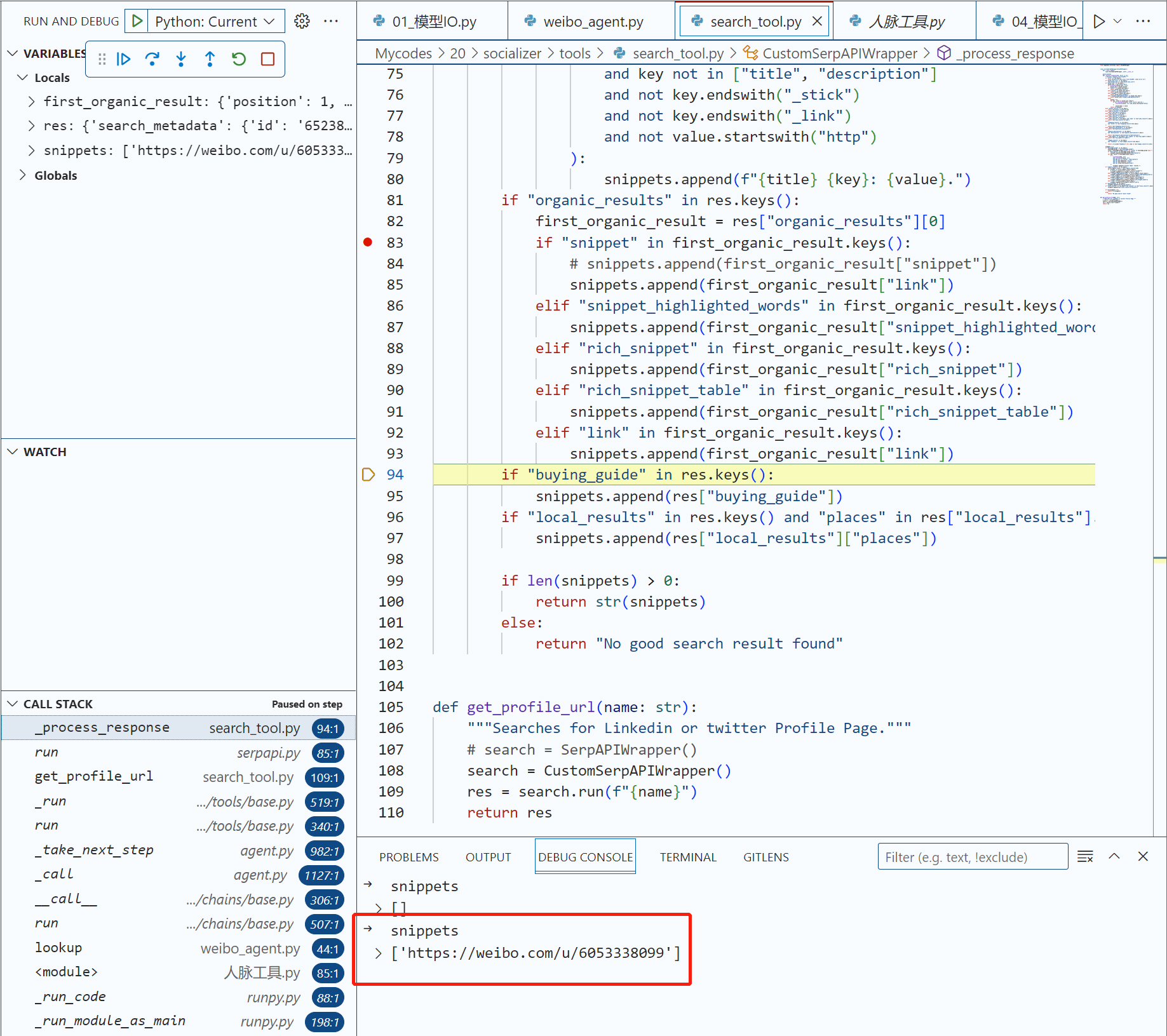
@staticmethod def _process_response(res: dict) -> str: """Process response from SerpAPI.""" if "error" in res.keys(): raise ValueError(f"Got error from SerpAPI: {res['error']}") if "answer_box_list" in res.keys(): res["answer_box"] = res["answer_box_list"] '''删去很多无关代码''' snippets = [] if "knowledge_graph" in res.keys(): knowledge_graph = res["knowledge_graph"] title = knowledge_graph["title"] if "title" in knowledge_graph else "" if "description" in knowledge_graph.keys(): snippets.append(knowledge_graph["description"]) for key, value in knowledge_graph.items(): if ( isinstance(key, str) and isinstance(value, str) and key not in ["title", "description"] and not key.endswith("_stick") and not key.endswith("_link") and not value.startswith("http") ): snippets.append(f"{title} {key}: {value}.") if "organic_results" in res.keys(): first_organic_result = res["organic_results"][0] if "snippet" in first_organic_result.keys(): # 此处是关键修改 # snippets.append(first_organic_result["snippet"]) snippets.append(first_organic_result["link"]) elif "snippet_highlighted_words" in first_organic_result.keys(): snippets.append(first_organic_result["snippet_highlighted_words"]) elif "rich_snippet" in first_organic_result.keys(): snippets.append(first_organic_result["rich_snippet"]) elif "rich_snippet_table" in first_organic_result.keys(): snippets.append(first_organic_result["rich_snippet_table"]) elif "link" in first_organic_result.keys(): snippets.append(first_organic_result["link"]) if "buying_guide" in res.keys(): snippets.append(res["buying_guide"]) if "local_results" in res.keys() and "places" in res["local_results"].keys(): snippets.append(res["local_results"]["places"])
if len(snippets) > 0: return str(snippets) else: return "No good search result found"
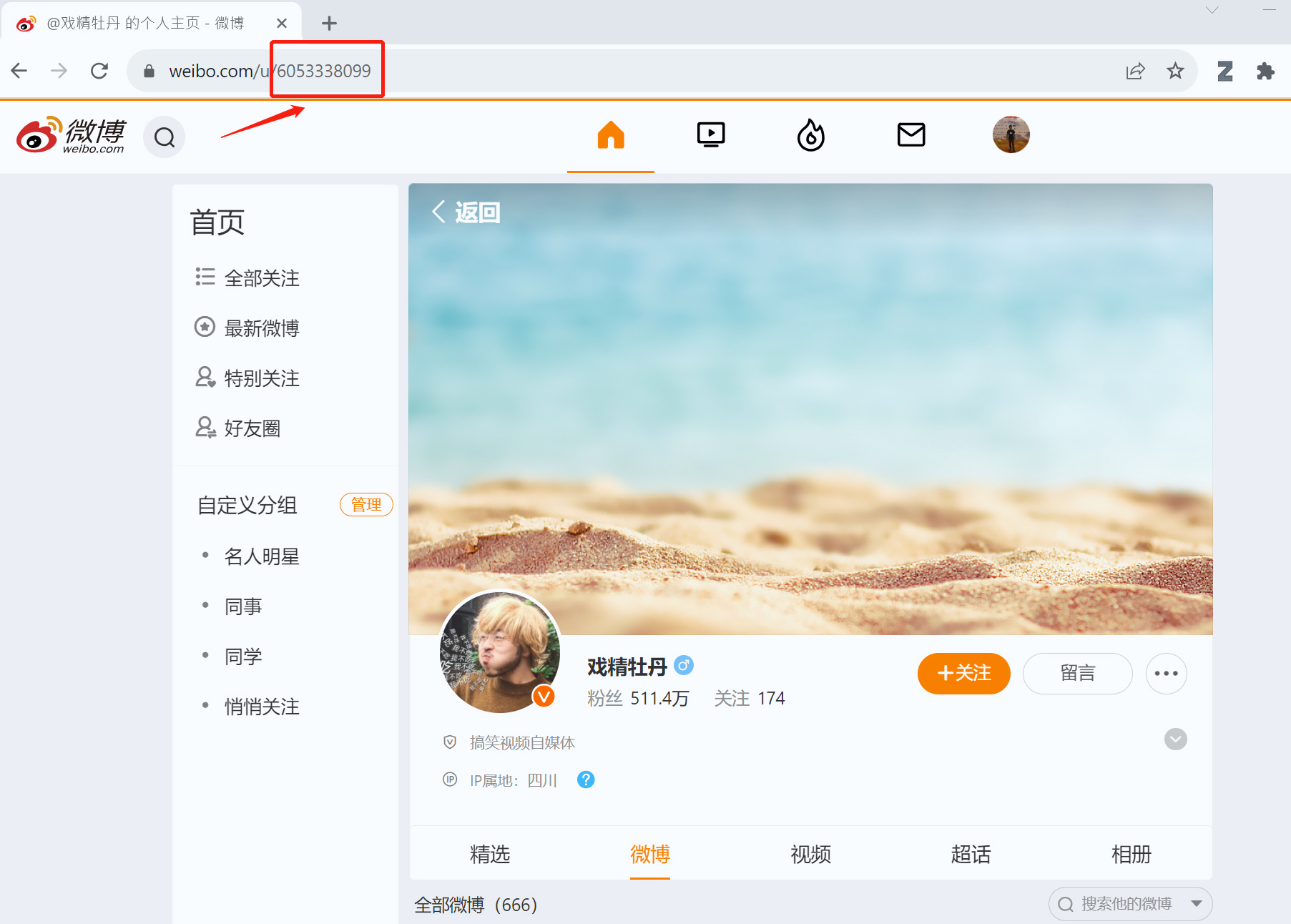
# 获取与某种鲜花相关的微博UID的函数 def get_UID(flower: str): """Searches for Linkedin or twitter Profile Page.""" # search = SerpAPIWrapper() search = CustomSerpAPIWrapper() res = search.run(f"{flower}") return res
唯一的区别就是,我们在下面的逻辑中返回了link,而不是snippet。
1 2 3 4 5
if "organic_results" in res.keys(): first_organic_result = res["organic_results"][0] if "snippet" in first_organic_result.keys(): # snippets.append(first_organic_result["snippet"]) snippets.append(first_organic_result["link"])
# 设置OpenAI API密钥 import os os.environ["OPENAI_API_KEY"] = 'Your OpenAI API Key' os.environ["SERPAPI_API_KEY"] = 'Your SerpAPI Key'
# 导入所取的库 import re from agents.weibo_agent import lookup_V from tools.general_tool import remove_non_chinese_fields from tools.scraping_tool import get_data
def remove_non_chinese_fields(d): if isinstance(d, dict): to_remove = [key for key, value in d.items() if isinstance(value, (str, int, float, bool)) and (not contains_chinese(str(value)))] for key in to_remove: del d[key] for key, value in d.items(): if isinstance(value, (dict, list)): remove_non_chinese_fields(value) elif isinstance(d, list): to_remove_indices = [] for i, item in enumerate(d): if isinstance(item, (str, int, float, bool)) and (not contains_chinese(str(item))): to_remove_indices.append(i) else: remove_non_chinese_fields(item) for index in reversed(to_remove_indices): d.pop(index)