你好,我是何辉。今天我们继续学习Dubbo拓展的第三篇,注册扩展。
和前端进行联调测试,想必你再熟悉不过了,在这个阶段,前端为了能调用到指定的网关服务,一般会在请求 URL 中,把域名替换为具体的 IP,然后请求网关,进行功能联调测试。
但是大多数功能的核心逻辑,不在网关,而是在后端应用,那就意味着,网关接收到前端请求后,还得再调用其他后端应用,但是,后端应用系统会部署在测试环境的多个 IP 节点上。那,网关怎么知道要调用后端应用哪个 IP 节点呢?
按“[温故知新]”学过的负载均衡策略,你可能会说,网关根据调用接口,负载均衡到任意一个 IP 节点就行了。
可是,你忽略了一个重要因素,在需求并行迭代开发的节奏下,不同的 IP 节点,可能部署的是你这个后端应用的不同版本,如果让网关负载均衡,我们怎么能保证每次前端发起的请求,都会命中需要测试的那个后端应用 IP 节点呢?
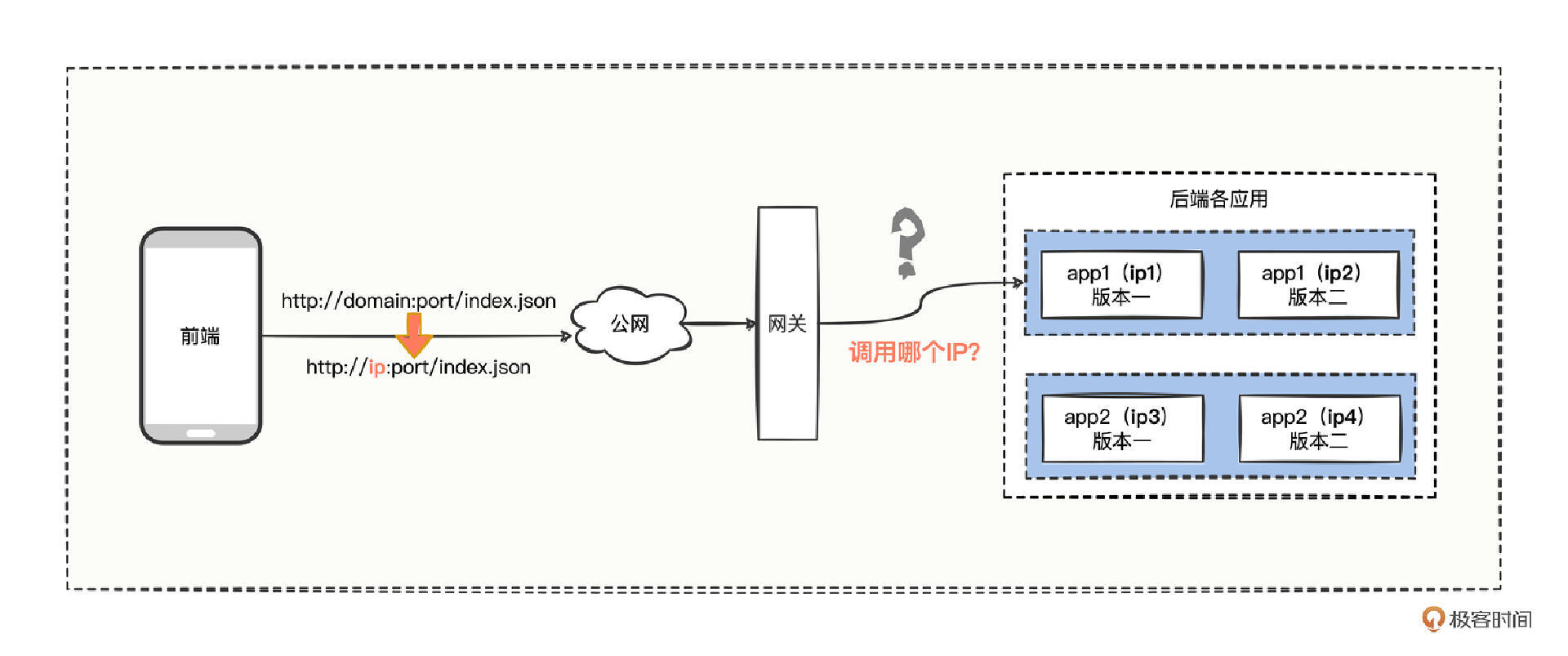
就像图中,有一个网关,两个后端应用 app1 和 app2,app1 的两个迭代版本分别部署在 ip1 和 ip2 节点上。现在,前端通过指定 IP 请求到了网关,网关继续调用 app1,该调用 app1 的 ip1 节点,还是 ip2 节点呢?网关是负载均衡调用,还是指定 app1 的 IP 调用呢?
对于这种需要把请求,路由到指定的后端应用 IP 节点的情况,该怎么处理呢?
手动配置 IP
你可能会说,既然网关不知道调用 app1 的哪个 IP,是不是可以想办法指定一下?
指定 IP 的确是个好思路,至少可以使网关调用到精准的 IP 节点。但是这个 IP 该配置在哪里呢?
这简单,回忆在“[点点直连]”中学过的,我们在 dubbo:reference 标签或者 @DubboReference 注解中,指定 url 属性值为需要调用的 IP 地址,应该就可以了。
1 | <dubbo:reference url="dubbo://[机器IP结点]:[机器IP提供Dubbo服务的端口]" /> |
确实可以。那我们延申一下,若 app1 需要调用 app2 呢,那在 app1 调用 app2 的接口上,是不是也得设置 url 属性来指向 app2 的 IP 地址呢?以此类推,如果功能比较复杂,不是简简单单两三个调用能结束的,得在多少个接口上添加 url 属性指向下一个 IP 节点。
所以,考虑到功能场景的差异,我们要分情况看待,在没有丰富的生态环境情况下。
- 若项目小而轻量级,通过指定 url 属性不失为一种最快的方式。修改代码设置 url 属性,然后打个包再部署一下,也就几分钟的事情,无疑是简单粗暴高效的(在代码封板前,记得把 url 属性删掉)。
- 若项目牵连的系统比较多,修改 url 属性外加打包部署,是一笔不小的重复劳动力开销,而且万一物理机出故障了,物理机上的所有虚拟机 IP 节点会彻底失去服务能力。如果再重新创建一批新的 IP 节点,又得修改一堆的系统代码全部指向新的 IP 节点,效率太差。
既然改代码这么麻烦,你肯定也想到了新想法——变成可配置化形式,就不必再为了修改代码、打包和部署而烦恼了。
一想到配置化的形式,回忆之前在“[配置加载顺序]”中学过的四层配置覆盖关系,System Properties 优先级最高,Externalized Configuration 次之,API / XML / 注解的优先级再低一点,Local File 优先级最低。

我们可以在 System Properties、Externalized Configuration 两个层级进行动态化的配置,立马就解决了先前的硬编码形式,效率有了大大的提升。
配置形式,我举 2 个例子。
1 | /////////////////////////////////////////////////// |
第一个是在 System Properties 层级中,通过 -D 来添加 JVM 启动参数。-D 的参数名是由“dubbo.reference + 接口类路径 + url”构成的,类似 dubbo.reference.com.hmily.dubbo.api.UserQueryFacade.url 这种形式,与硬编码书写形式有点不同,不过,参数值还是硬编码书写的老样子。
第二个是在 Externalized Configuration 层级中,往配置文件中添加 -D 后面的参数名和参数值。
不过,我们现在是人为手动去动态配置 IP 的,如果想再偷懒一些,连手动配置的这个环节也省掉,完全靠系统自己去选择精准的 IP,该怎么处理呢?
自动识别 IP
其实,只要你“认真偷懒”,继续抽象重复的事情,还是能找出一些稀有的解决方案的。
既然要省去手动配置 IP 环节,那就一定遇到了如何从多个 IP 中精准选择的问题。
如果想靠消费方自发自动地找到正确 IP ,一定得提供一些易于被程序识别的标识,让消费方通过识别指定的标识找到具体的 IP,这么一来,好像解决了手动配置的环节,值得尝试一下。
所以,接下来的问题就变成了,**怎么给众多的 IP 提供一些易于被识别的标识?**我们继续思考。
之前手动配置的 IP 地址,是在 dubbo:reference 标签或者 @DubboReference 注解中通过添加 url 属性来搞定的,而 url 属性值的解析处理,是由 Dubbo 框架层面完成的。所以,解析逻辑,我们很难人为介入控制,即使控制了,还得为 Dubbo 框架使用 url 属性值的地方做兼容考虑,工作量肯定不小。因此为 IP 添加标识这个事,继续打 url 属性的主意会越走越歪,我们得另辟蹊径。
你可能觉得有点难找到突破点,别着急,我分享一个小技巧,在抽象的时候,我们可以先梳理整个功能的流程,然后反复琢磨每个步骤,看看是否能撕开一个口子做扩展,通过少量的代码编写来完成抽象的能力。
按照小技巧的说法,我们想在消费方调用提供方时,通过一些标识,来精准找到指定的 IP 进行远程调用,那回忆一下“[调用流程]”中的各个步骤,看看能否找到惊喜。看我们当时画的调用流程的总结图。

在 Cluster 层次模块中,有个故障转移策略的调用步骤,通过重试多次来达到容错目的,恰好这里能拿到多个提供者的 invoker 对象,每个 invoker 对象中就有提供方的 IP 地址。
这就好办了,到时候只要从多个 invoker 对象中选出一个具体的 invoker 对象就可以了,至于 IP 标识,我们还是不能直接在 IP 地址内容中添加一些东西,因为一旦添加,源码中好多用到 IP 的地方都得做相应的调整,不可行。那我们干脆在 invoker 中添加一个新字段,通过循环 invoker 对象列表的新字段,貌似也能拿到精准的 invoker 对象。
所有,现在问题变成了,怎么给 invoker 对象增加一个新字段?
invoker 是框架层面实打实的硬编码类,想要修改可能有点难,我们得采取一种巧妙的方式,看看这个 invoker 有没有一些扩展属性的字段能用的。我们之前在“[配置加载顺序]”中见过 invoker 内部的一些属性,看当时的截图。

果然,我们找到了一个 urlParam 参数,可以在 urlParam 中添加一个新字段,这样一来,我们只需要循环 invoker 列表中的 urlParam 属性,寻找含有新字段的 invoker 对象就可以了。
而且,因为 invoker 对象中的 urlParam 属性,在消费方的首次订阅和后续节点变更时,都会从 ZooKeeper 拉取最新的数据,这就意味着,到时候只要让提供方把这个新字段写到 ZooKeeper 中就行了。
怎么往 ZooKeeper 写数据,我们之前也学过,在“[发布流程]”中讲 RegistryProtocol 的 export 方法中,有一段向 ZooKeeper 写数据的代码,这里我也复制过来了。
1 | /////////////////////////////////////////////////// |
再细看这段代码,我们只需要认真研究 getRegistry 方法,拿到一个新的实现类就好了,利用这个新的实现类,把新字段写到 ZooKeeper 中。
注册扩展
接下来就来研究怎么扩展 Registry 接口,看看怎么从 getRegistry 方法中拿到另外一个新实现类。
话不多说,我们直接进入 getRegistry。
1 | /////////////////////////////////////////////////// |
方法非常简短,可以得到 2 个重要结论。
- 拿到了 RegistryFactory 接口的自适应扩展点代理对象。
- 把注册的地址 registryUrl 对象传入代理对象中,然后返回一个可以向注册中心进行写操作的实现类。提供方,如果是接口级注册模式,拿到的是 ZookeeperRegistry 核心实现类,如果是应用级注册模式,拿到的是 ServiceDiscoveryRegistry 核心实现类。
我们的需求是扩展 Registry 接口,看看怎么从 getRegistry 方法中拿到另外一个新实现类。
现在可以锁定一个重要的 RegistryFactory 接口,它的实现类也有两个 ServiceDiscoveryRegistryFactory、ZookeeperRegistryFactory,而且两个都重写了 createRegistry 方法。虽然,功能侧重点不同,但这两个类实现思路是一样的,任意模仿一个就行, 这里我就挑 ZookeeperRegistryFactory 来模仿。
仿照 ZookeeperRegistryFactory 和 ZookeeperRegistry 两个类来写,能继承使用的话就继承使用,不能继承的话可以考虑简单粗暴的 copy 一份。
1 | /////////////////////////////////////////////////// |
改造后的代码关注 4 点。
- 复制了 ZookeeperRegistryFactory 的源码,并改了个名字为路由编码注册工厂(RouteNoZkRegistryFactory),其中,重写了 createRegistry 方法,返回了自己创建的路由编码注册器(RouteNoZkRegistry)。
- 在路由编码注册器(RouteNoZkRegistry)中,主要继承了已有的 ZookeeperRegistry 类,并重写了注册与注销的方法,在两个方法中都额外添加了一个新字段 routeNo 属性,属性值为当前 IP 机器易于识别的简单别名。
- 把路由编码注册工厂(RouteNoZkRegistryFactory)添加到资源目录对应的 SPI 接口文件中(/META-INF/dubbo/org.apache.dubbo.registry.RegistryFactory)。
- 在设置注册中心地址时,把已有的 zookeeper 替换为 routenoregistry。
1 | /////////////////////////////////////////////////// |
写好之后,相信你迫不及待想验证一下了,我们写测试代码。
1 | /////////////////////////////////////////////////// |
测试代码也比较简单,就是想在消费方调用时,借用自定义的集群包装类,打印一下内存中的 invoker 信息,看看到底有没有拉取到提供方设置的 routeNo 标识。
接下来就是见证奇迹的时刻了,运行一下看打印结果。
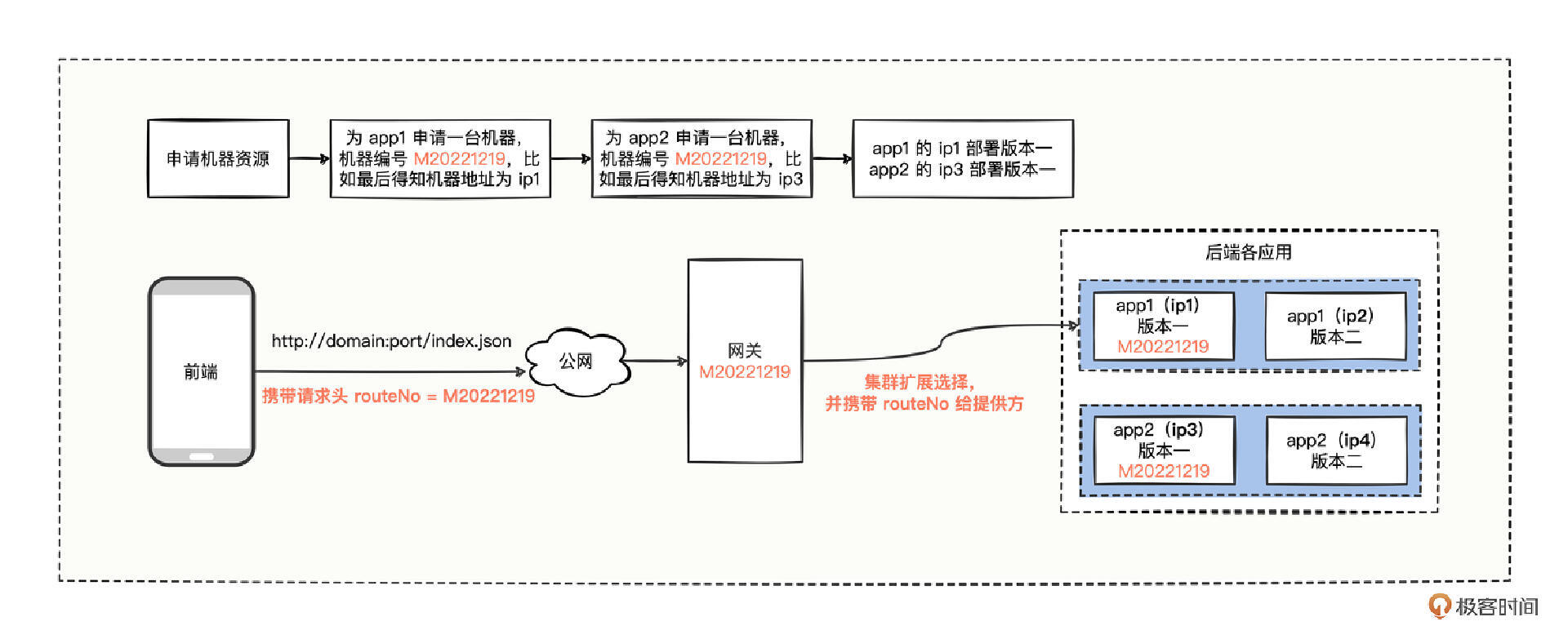
invoker信息:interface com.hmilyylimh.cloud.facade.demo.DemoFacade -> dubbo://192.168.100.183:28250/com.hmilyylimh.cloud.facade.demo.DemoFacade?anyhost=true&application=dubbo-25-registry-ext-provider&background=false&category=providers,configurators,routers&check=false&deprecated=false&routeNo=M20221219&dubbo=2.0.2&dynamic=true&generic=false&interface=com.hmilyylimh.cloud.facade.demo.DemoFacade&methods=sayHello,say&pid=8512&qos.enable=false&release=3.0.7&service-name-mapping=true&side=provider&sticky=false
从打印的日志中,看到了 routeNo 字段(加粗显示的部分),说明我们使用注册扩展的方式,通过新增一个 routeNo 字段,消费方可以根据这个标识来自动筛选具体 IP ,省去了手工动态配置 IP 的环节了,彻底解放了我们开发人员的双手。
写好注册扩展机制,已经完成了动态路由最重要的一环,不过,其他辅助的操作也不能落下,主要有 3 个关键点。
- 在申请多台机器的时候,可以自己手动为这一批机器设置一个别名,保证分发路由注册器中 appendrouteNo 能读取到整个别名就行。
- 在消费方自定义一个集群扩展器,把集群扩展器中的 invoker 列表按照 routeNo 进行分组后,再从接收请求的上下文对象中拿到 routeNo 属性值,从分组集合中选出过滤后的 invoker 列表,最后使用过滤后的 invoker 进行负载均衡调用。
- 前端若需要在哪个环境下测试,就在请求头中设置对应的 routeNo 属性以及属性值,这样就充分通过 routeNo 标识,体现了不同环境的隔离。
注册扩展的应用
注册扩展如何使用,想必你已经非常清楚了,在我们日常开发的过程中,哪些场景会使用到注册扩展呢?我举 3 个常见的应用场景。
第一,添加路由标识,统一在消费方进行动态路由,以选择正确标识对应的 IP 地址进行远程调用。
第二,添加系统英文名,统一向注册信息中补齐接口归属的系统英文名,当排查一些某些接口的问题时,可以迅速从注册中心查看接口归属的系统英文名。
第三,添加环境信息,统一从请求的入口处,控制产线不同环境的流量比例,主要是控制少量流量对一些新功能进行内测验证。
总结
今天,我们从一个简单联调测试场景开始,思考提供方应用如果有多个 IP 节点部署时,消费方该如何精准选择提供方 IP 进行调用。
手动配置 IP 方案,采用最为常见的硬编码方式设置 IP,但是带来了无尽的重复工作量,每次修改 url 属性,都需要重新打包和部署,流程非常繁琐而且效率低下。可以采取配置化的方式,在 System Properties、Externalized Configuration 两个层级进行动态配置,减轻硬编码带来的繁琐工作量。
自动识别 IP 方案,旨在进一步省掉手动配置 IP 的工作量,我们分析消费方的调用流程,推导出提供方在注册应用时,需要新增一个 routeNo 字段,根据接收请求的上下文对象中 routeNo 字段值,从 invoker 列表中,过滤出符合条件的列表,然后复用已有的负载均衡策略,继续后续调用流程。
总结一下实现注册扩展的偷懒三部曲。
- 首先,找到 RegistryFactory 已有的实现类,挑选一个最贴近诉求的实现类研究,至于是考虑改造已有代码,还是继承实现类重写个别方法,根据具体情况而定。
- 然后,把扩展注册工厂的实现类,添加到资源目录对应的 SPI 接口文件中。
- 最后,把注册中心地址的协议类型,修改为刚刚新增实现类的扩展点名称。
注册扩展的三个经典应用场景,添加路由标识、添加系统英文名、添加环境信息。
思考题
留个作业给你,实现注册扩展后,还有其他的辅助操作功能,请你试着在消费方自定义一个集群扩展器,从接收请求的上下文对象中拿到 routeNo 属性值,进行分组过滤,然后用过滤后的 invoker 进行后续的调用流程。
期待在留言区看到你的思考,参与讨论。如果觉得今天的内容对你有帮助,也欢迎分享给身边的朋友一起讨论,可能就帮TA解决了一个困惑。我们下一讲见。
24 思考题参考
上一期留了个作业,在消费方提供一套针对敏感字段进行加密的过滤器。
想要解答这个问题,其实很简单,就是与解密过滤器形成对称反向操作,唯一不同的地方,就是将解密操作改为加密操作,其他环节变化不大,看流程图。
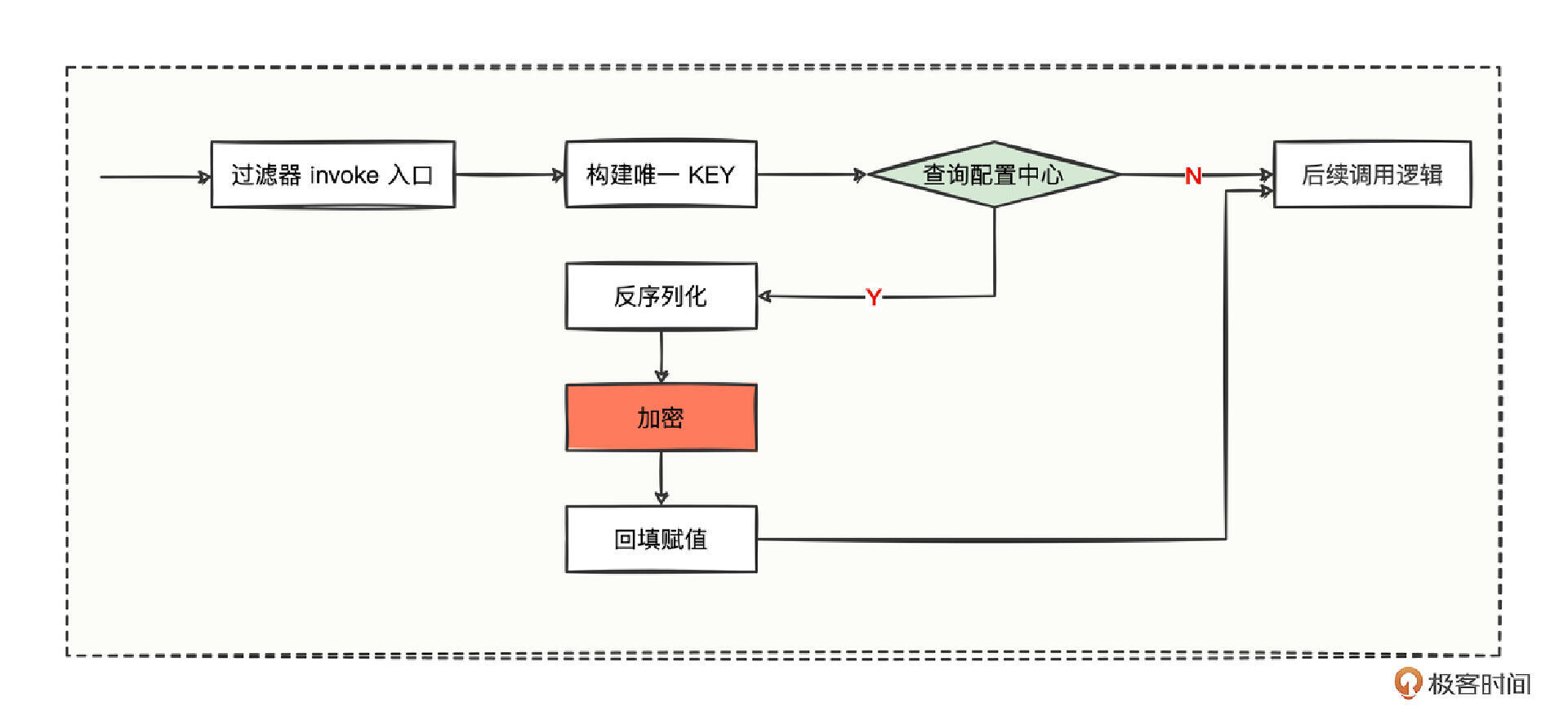
代码主要有 4 个步骤。
- 第一,新增 EncryptConsumerFilter 加密过滤器,并且设置 @Activate 的 group 属性值作用于消费方。
- 第二,修改构建唯一 KEY 值的规则,再添加一个 side 的维度,side 的值为 consumer。
- 第三,将解密操作替换为加密操作。
- 第四,在消费方的资源目录中添加加密过滤器的配置。
有了这 4 步的设计,改造起来也非常简单。
1 | /////////////////////////////////////////////////// |
你写完加密过滤器,会发现和解密过滤器真是太像了,逻辑大多一样。
如果你有兴趣,也可以考虑把两者合二为一,写成一个过滤器处理,更长远考虑,可以把这个加解密过滤器单独封装成一个插件,以后哪个系统需要安全整改敏感信息字段加密,直接把这个插件引用过滤,然后对相应的敏感字段添加配置中心值就行了,无需改动任何业务代码进行加解密操作。