你好,我是金伟。
通过之前的课程,相信你已经对AI智能体应用开发有了一定的认识,从这节课开始,我们深入学习大模型微调这项技术,从一个具体的项目需求出发,一步步把大模型微调和专有模型开发应用到项目里。
说起大模型微调,很多同学容易出现拿着锤子找钉子的情况,认为什么问题都要通过大模型微调来解决。需要注意的是,并不是一切问题都需要大模型微调。
以本节课的电商客服项目为例,我会通过对比之前的智能客服方案,说明大模型微调到底是什么,适合什么场景,以及为什么最终会在电商客服的项目里用微调训练的技术。
电商客服项目的特点
目前已有的传统智能客服方案往往采用的是规则化的方法。它的核心就是总结人工坐席遇到的客服场景,形成固定规则的客服回复,帮坐席节省大量的时间。
比如一个虚拟产品,自动发货,客户下单后可能会着急询问,问出的内容各不相同,那我们可以总结类似的问题,一一匹配问题和回答。
1 | ##客户下单后可能马上提问: |
但是呢,规则化的方法只能按规则逻辑回复,一旦遇到超出规则的问题就需要匹配人工坐席处理。总的来说,这类处理方案有两大缺陷。
- 上下文理解能力和泛化能力不足。不能识别客户情绪,做不到个性化,大部分问题要依赖人工坐席。
- 知识库和话术更新成本高。传统的方案面对简单问题还可以,一旦问题复杂就歇菜了。
而这些问题,我们都可以交给大模型来解决。
设计一个大模型客服
在前面的课程中,我们提到一个优秀的客服提示词,那基于大模型的客服方案是不是这样一个提示词就能搞定呢?不是的。
方案选型
为了解决单一提示词方案能力不足的问题,我还需要把客服话术整体加入提示词。
1 | 【智能客服提示词】 |
你如果熟悉提示词,会发现这个方案确实可以让大模型学习原有的客服话术,即使遇到新的问题,大模型也能应对自如。
不过,在客服话术很长的情况下,每次交互的token消耗会很大,导致费用很高。除了这一点,提示词的方案无法建立品牌调性以及自我认知,可控性不强。最关键的问题在于,提示词的方案没办法应对实时的产品信息查询,对知识更新不够友好。
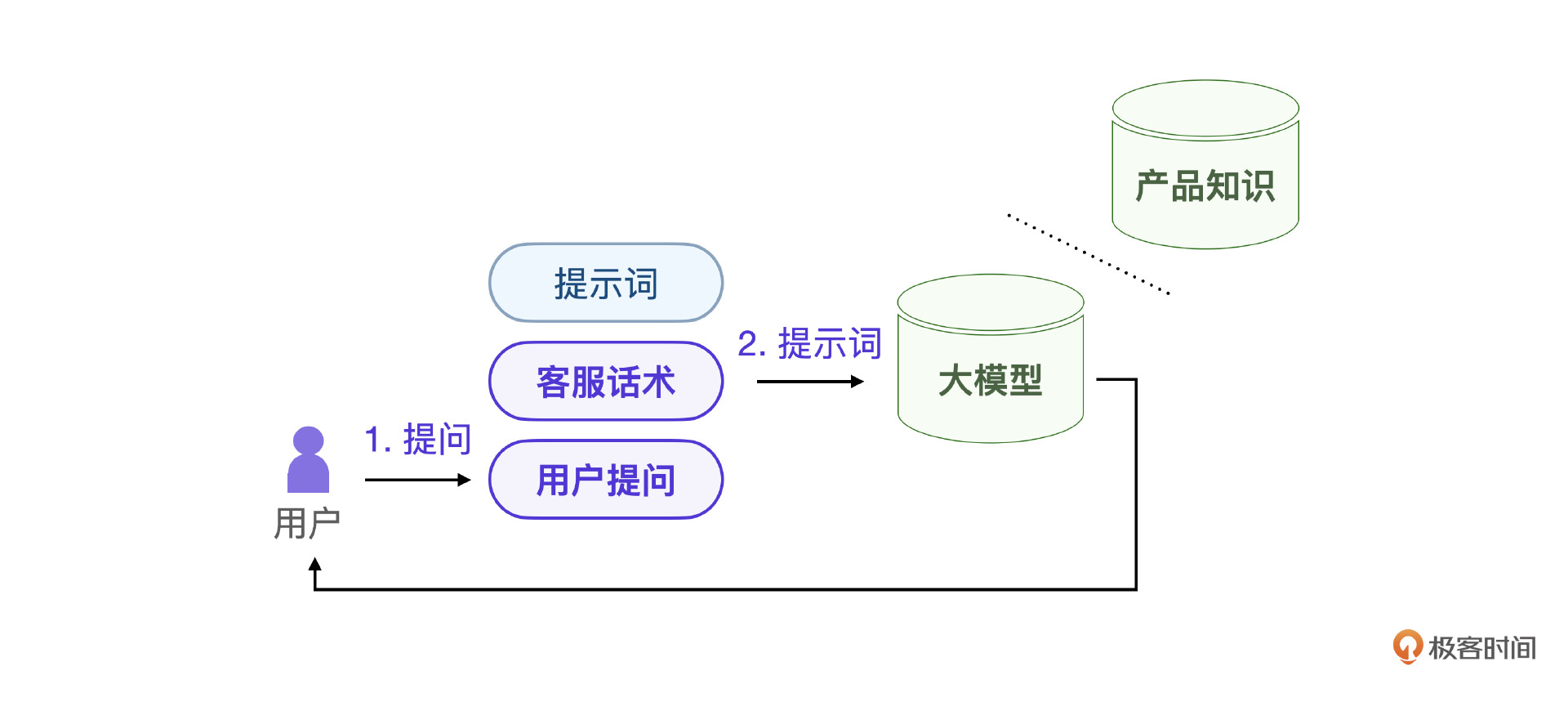
要解决知识检索问题,目前最有效的方法是采用RAG方案。这个方案的基本思想是每次用户提问的时候,都拿这个提问内容去向量数据库查询相似的知识,把查询到的知识作为提示词的补充内容提交给大模型。这样,大模型就能在足够的产品知识信息下回答了。
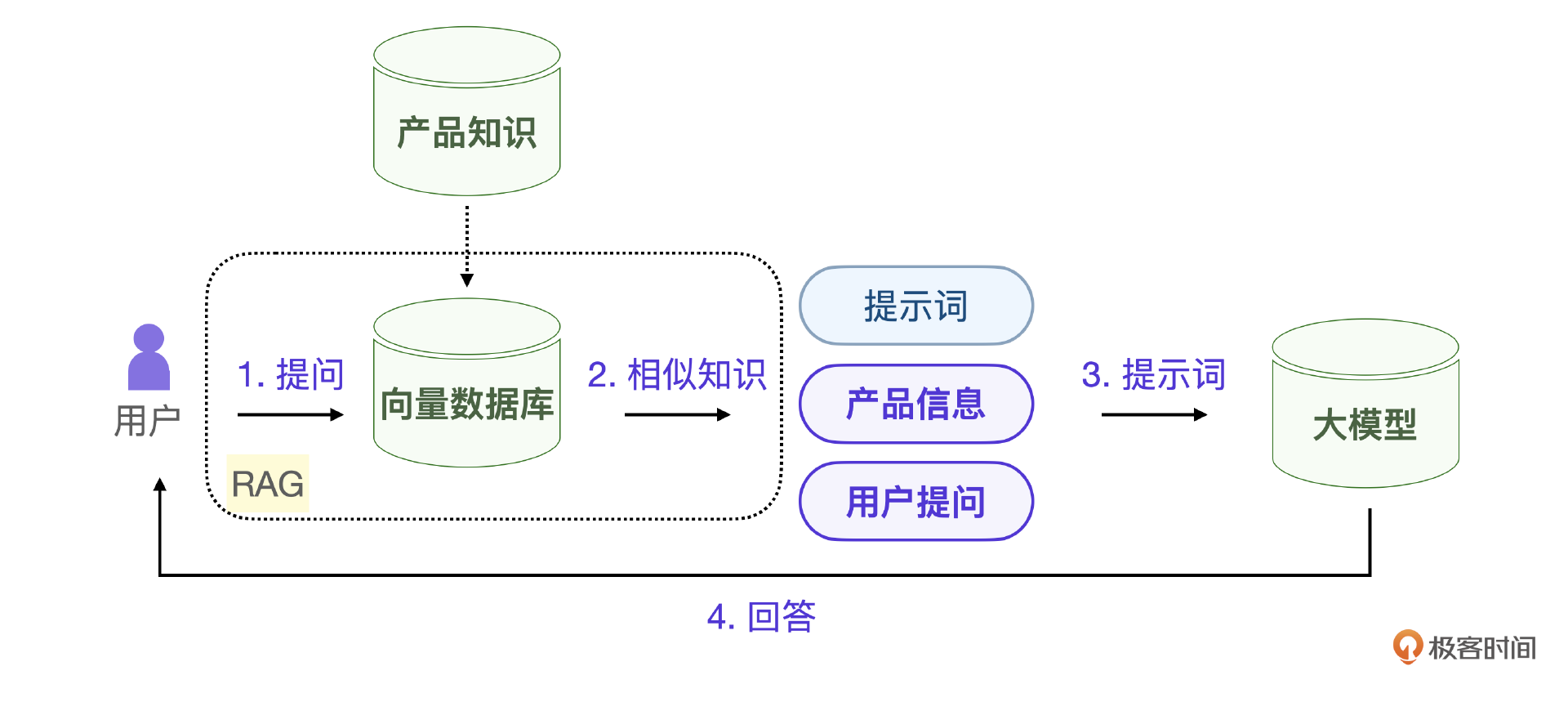
RAG方案的本质是通过向量查询确定抽取的信息。但是,如果用户上下文复杂,这种类似模糊查询的方法,不能准确定位用户真实意图,很可能查询到的产品信息是不精确的。
实际上,基于提示词+ RAG的方案已经可以实现80%的问题用智能客服替代,剩下的问题还是可以用人工坐席,如果想提高这个比例怎么办呢?这时候,就需要一个可以精确识别用户意图的方法了。
真实的智能客服项目的思路是用大模型先做用户意图识别,把问题分类,不同的问题用不同的方案。简单的问题用规则库和提示词解决,产品信息查询和知识类用RAG的方案,复杂用户问题识别和信息提取才需要微调,微调大模型能力之后,还是继续结合提示词+ RAG解决问题。
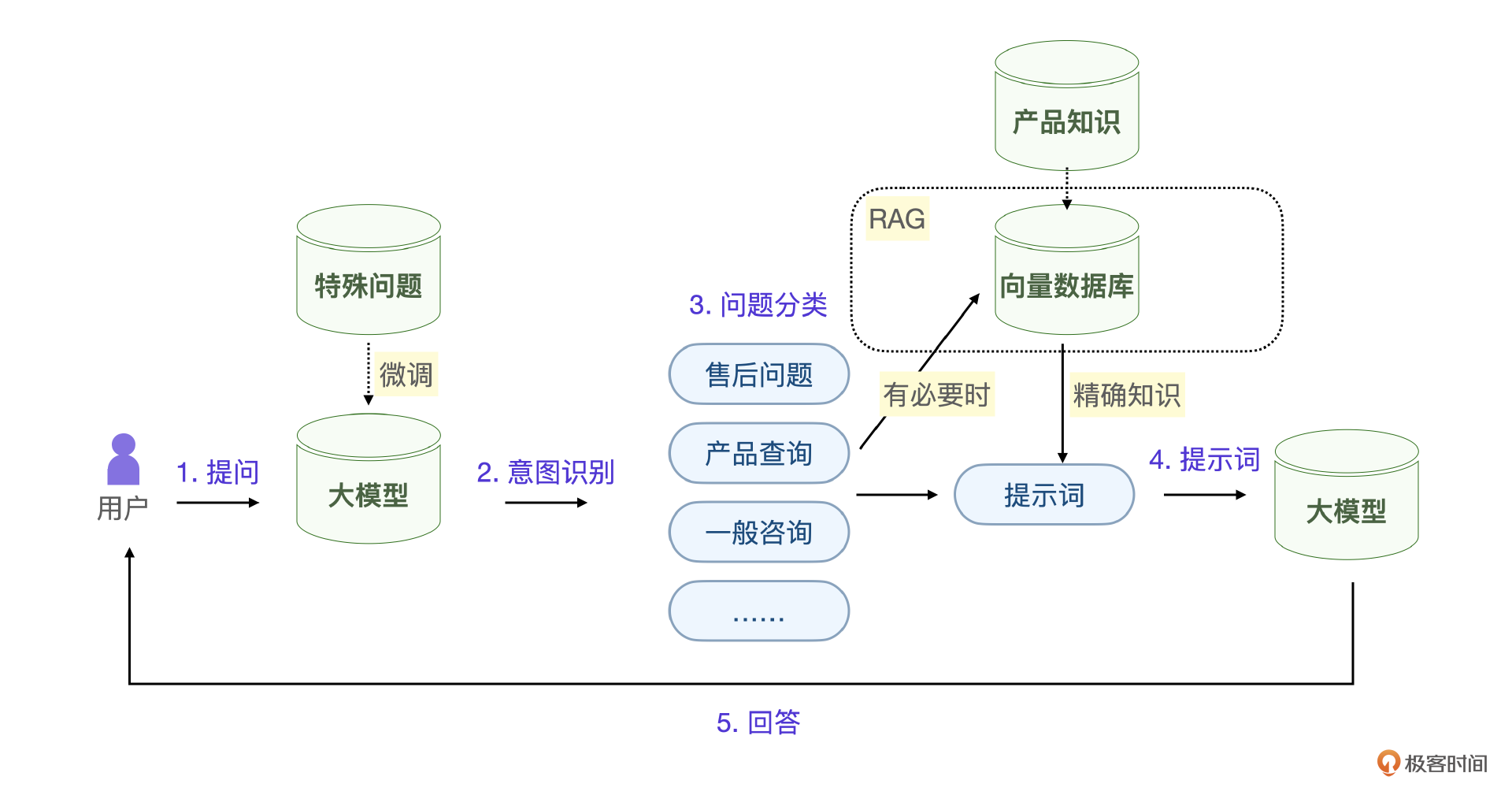
大模型微调相当于不断提示坐席的专业能力,让最后1%不可替代的部分也全部由智能客服替代。
这么说可能还是太抽象,接下来我就带你来搭建一个具体的智能客服智能体。
Dify智能体设计
智能客服本身也是一个Agent智能体应用。之前我们提到一些开发智能体的框架,比如Coze平台,Langchain开发框架等等。在智能客服项目里,我们选用Dify智能体开发框架,因为它同时具备定制的能力和拖拽式的编排界面,很方便。
在编排Dify智能体之前,我们需要回顾一下Agent智能体最核心的原理。
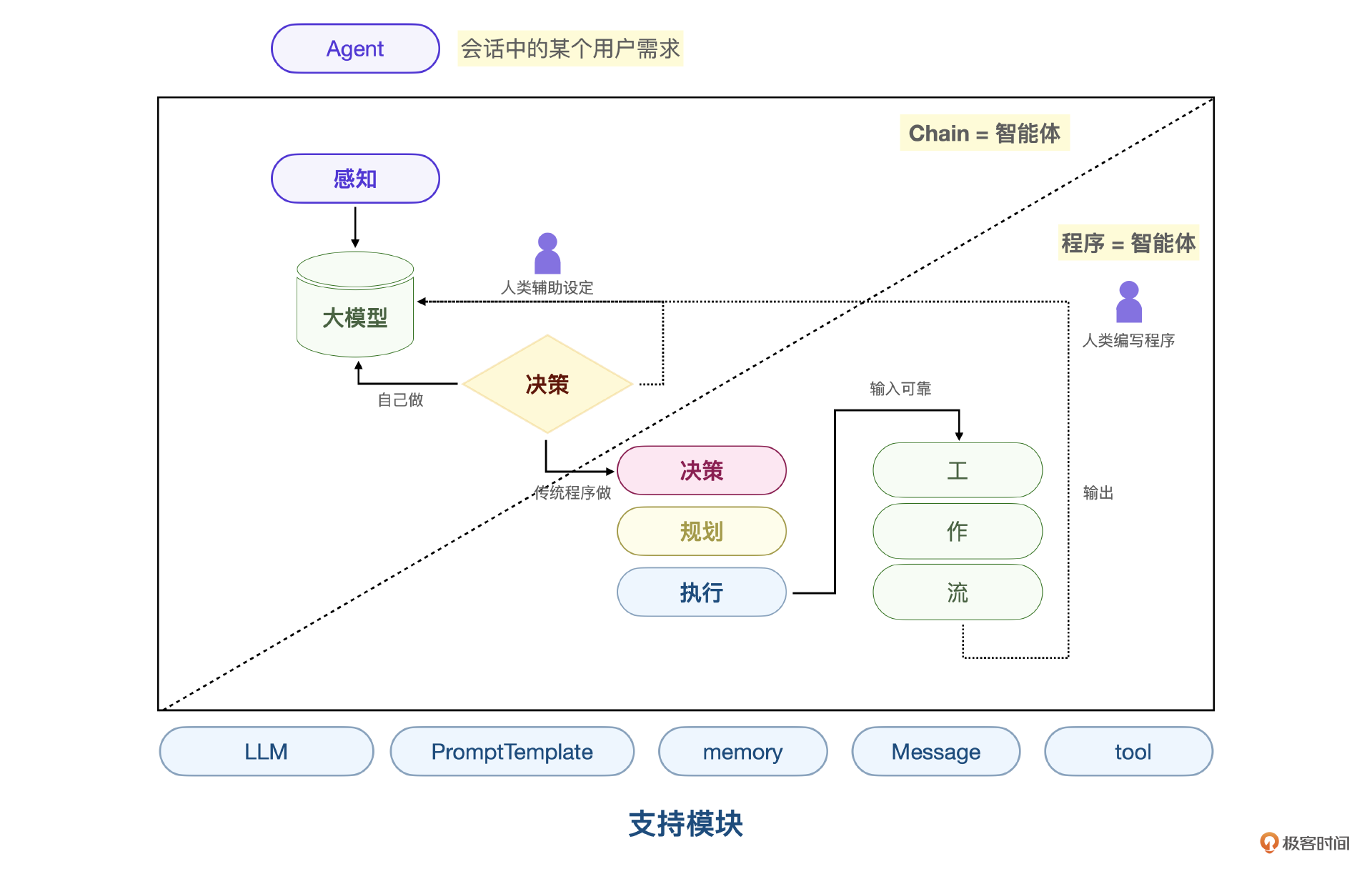
Agent智能体的核心逻辑就是意图识别和ReAct推理。意图识别简单来说就是根据上下文做问题分类,ReAct是一种推理框架。其中,Re=推理(Reasoning),Act=行动(Acting),Re推理可以简单地理解为在特定的问题分类下,准确地识别用户的上下文,获取解决这个问题需要的参数,Act行动则是具体解决这个问题的工作流程序逻辑。
在智能客服项目里,怎么让大模型准确的识别出问题分类和用户参数呢?只需要使用Dify框架下的 Chatflow。为了解决自然语言输入中用户意图识别的复杂性,Chatflow提供了问题理解类节点,我们把问题分类编辑好之后,就可以借助大模型完成用户意图识别了。
下图为产品客服场景的示例Chatflow模板。

我在这个示例模版里预制了3个问题分类:售后相关的问题,产品操作使用相关的问题,其他问题。
定义这些具体问题分类的描述,实际上就是在告诉大模型怎么做意图识别。每个问题分类后续工作流的输入参数定义,实际上就是在告诉大模型 Re推理应该从上下文提取哪些用户参数。最后工作流的具体逻辑就是实现 Act行动。
你可以想象系统内部有两个提示词。一个用于意图识别,一个用于ReAct。
1 | #意图识别 |
现在只需要根据我们场景下的客服问题编辑Chatflow即可。
比如编排一个工作流,处理订单催发货问题。第一步要在Chatflow中增加一个问题分类,需要注意,这个问题分类的描述会直接影响你的客服能不能把“催发货”这个问题分配到这个新的工作流上。
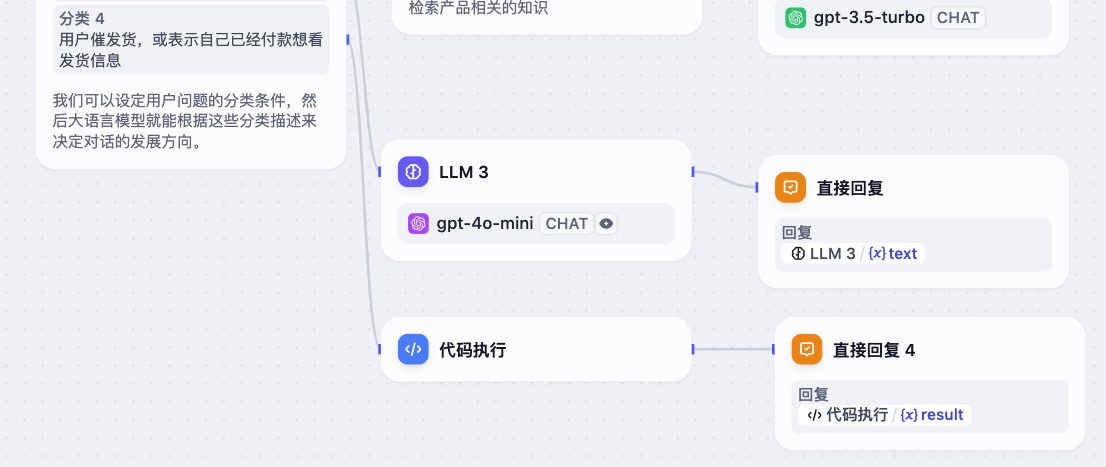
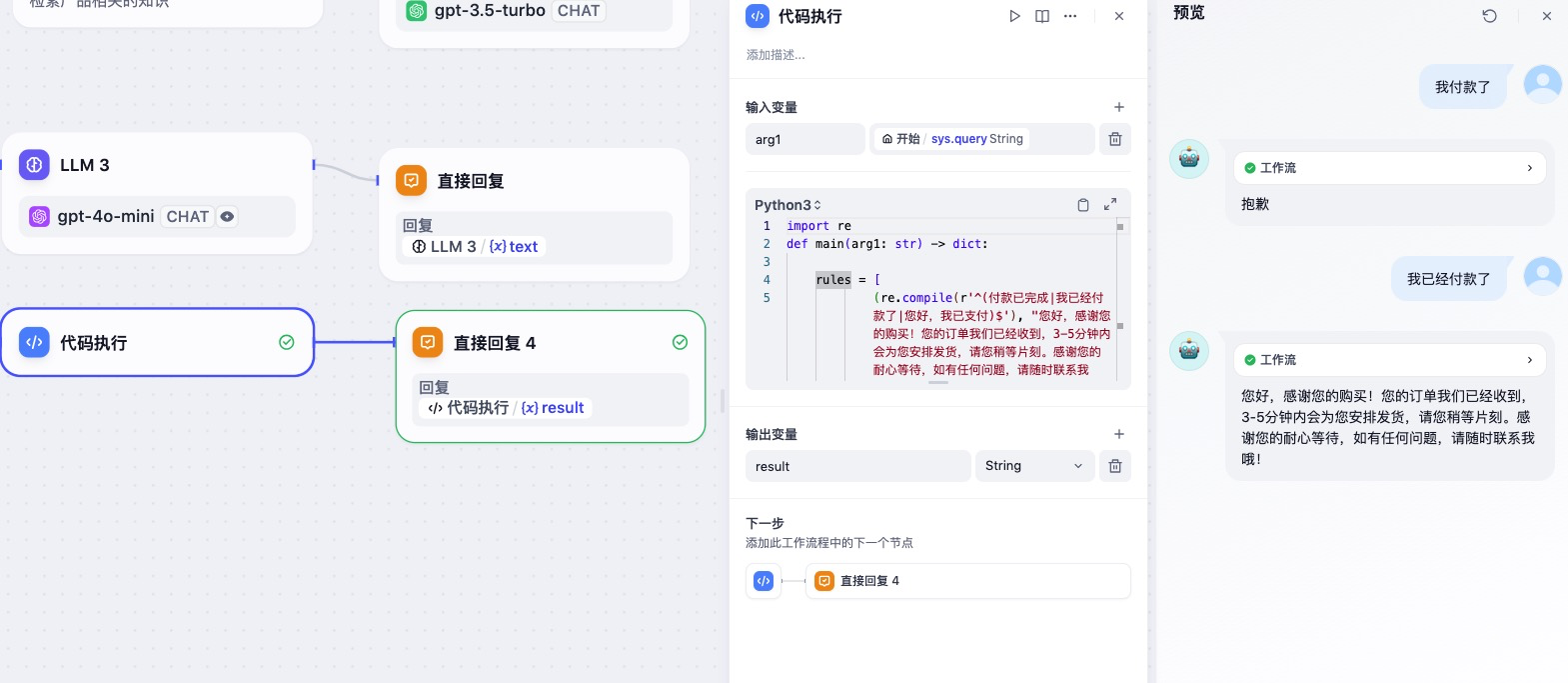
具体工作流逻辑可以直接集成 简单的话术,也就是常见的问题回复。实际也可以用刚才说的规则化脚本方式处理。下面是我集成了基础规则库的回复代码方案,以及最终智能客服的分类和执行效果。
第二个例子,实现一个产品查询的问题分类,更细分一下,是一个查询当地产品库存的问题分类。
第一步还是新建一个问题分类,让智能体在遇到库存问题时使用我们新建的工作流。
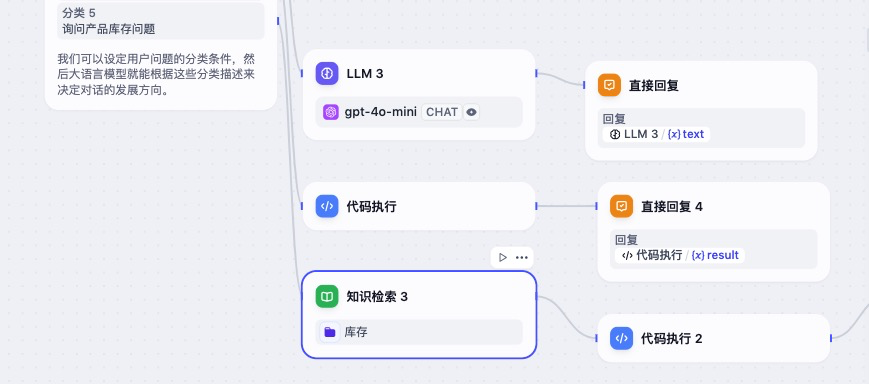
这个工作流的第一步就是做知识库检索,最后一步是用LLM结合查询结果回复用户。下面分别是知识库的数据和LLM的提示词。
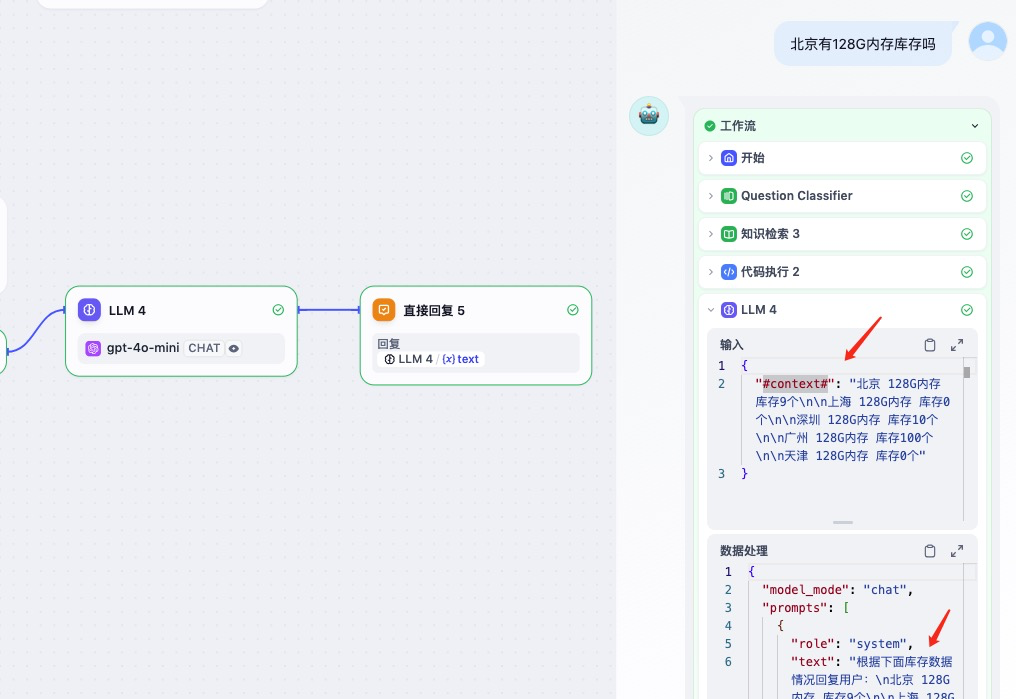
显然,现在已经可以实现意图识别,接下来就是结合知识库去查询具体产品了。当然,我们这节课的重点不是实现这个智能体工作流,而是要说清楚大模型微调的使用场景。
现在你可以想象一下,如果意图识别,问题分类和ReAct都准确,那么这个智能体框架就可以运行得很好,但其实还是可能会遇到问题。什么问题呢?通常是问题分类不准和 ReAct 不准确。这些问题就需要微调了,接下来进一步分析微调的场景。
什么时候选择微调大模型?
先下结论,正是由于意图识别和ReAct在特定环境下能力不足,我们才需要微调大模型适配这些场景。
这里面一个很重要的场景就是自我认知的微调。以我们客服项目里的电脑配件场景为例,如果直接使用通用模型进行客服服务,可能会因为原模型对技术性内容的理解不足,无法提供准确的解答。而经过微调后的模型,就像一个精通硬件的专家,可以为用户提供精准的产品建议和技术支持。
微调更重要的功能是在私有场景下的意图识别和数据抽取能力提升,比如文稿里的例子里,这位客户想要马上拿到这个产品,没经过微调的大模型在数据抽取能力上可能不足,无法通过智能客服处理,但是经过微调之后,这一类需求也可以自动处理了。
1 | 问:请问有没有兼容我笔记本型号的内存条? |
因此,在实际的Dify工作流中,要把公有大模型替换成我们微调后的私有大模型。
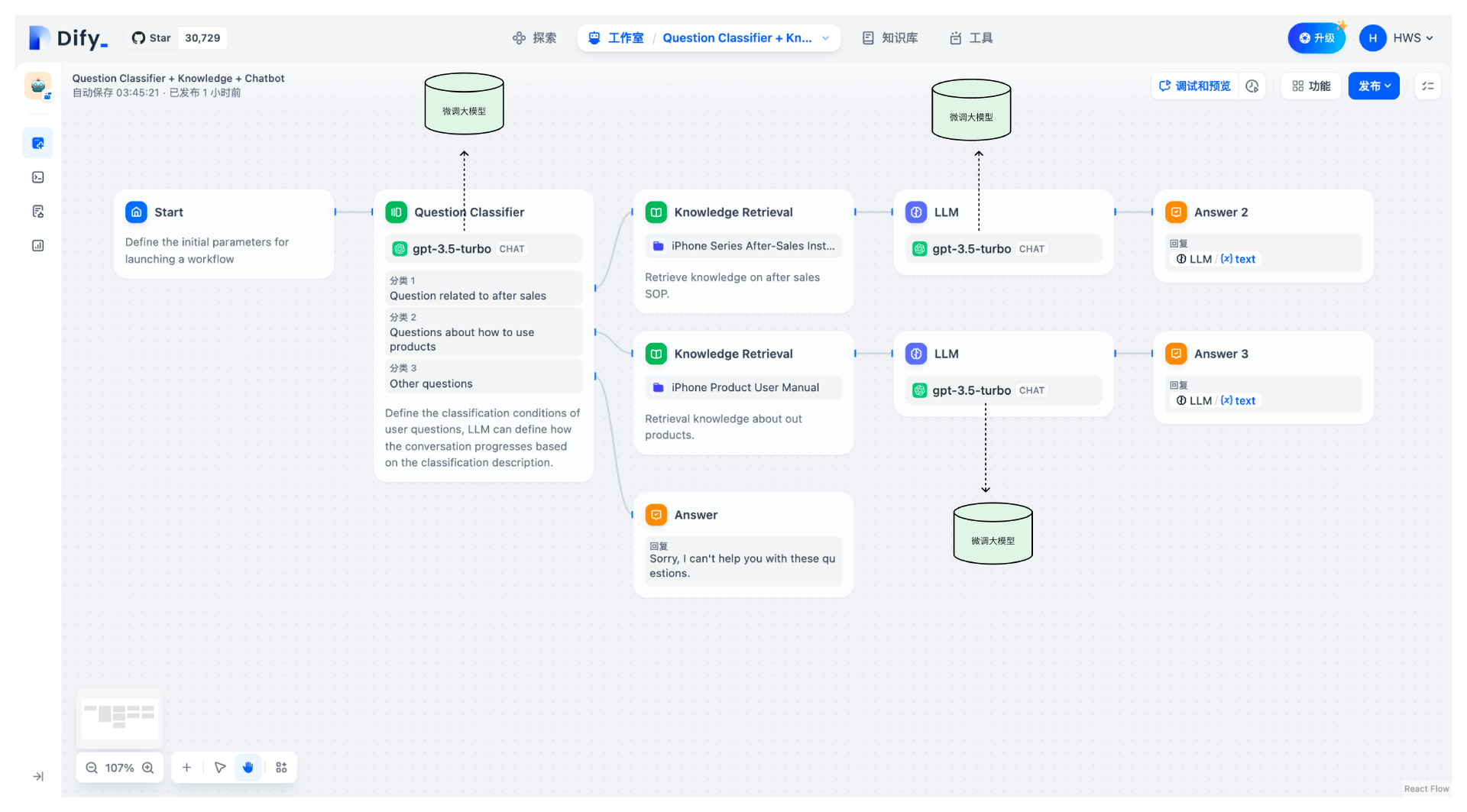
你看,实际项目中,我们不是预先选择微调大模型,而是当智能体遇到应用问题的时候,根据问题去调整大模型的单个能力,保留其他原有能力。
换句话说,微调思想并不是把数据写入大模型,而是调整大模型的能力,比如微调过程中利用大量的历史客户交互数据,大模型可以内化数据中潜在的客户需求和行为模式,从而做出比通用模型更好的响应,提高召回率。
自我认知微调
这节课我先以品牌认知微调为例,来说明我们具体是怎么微调大模型的。我们的最终目标是为模型提供清晰的自我认知,让模型的回应可以保持一致的品牌声音和专业性,提升品牌形象。
一个没有经过自我认知微调的大模型,对 你是谁 这个问题回答可能是“我是一个由谁谁谁开发的大语言模型”。

自我认知微调实质上就是通过多个自我认知的问答数据,让大模型调整自己的回答模型。从下面的训练数据直接看这个问题会比较清晰。
1 | [ |
你看,这份数据里的 <NAME> 和 <AUTHOR> 是变量,可以填入你自己的名称。这个数据集是公开的,所以如果你想完成自我认知的微调,只需要填充这个数据模版就能完成数据准备。你可以在课后社群资料的引导下做这个微调实验,采用微调框架界面化操作完成。我这里用的基础模型是 Qwen-7B-Chat 模型。
不过,意图识别提升和数据抽取能力提升相关的微调数据准备,就没有这么简单了,下节课会重点介绍这个部分。
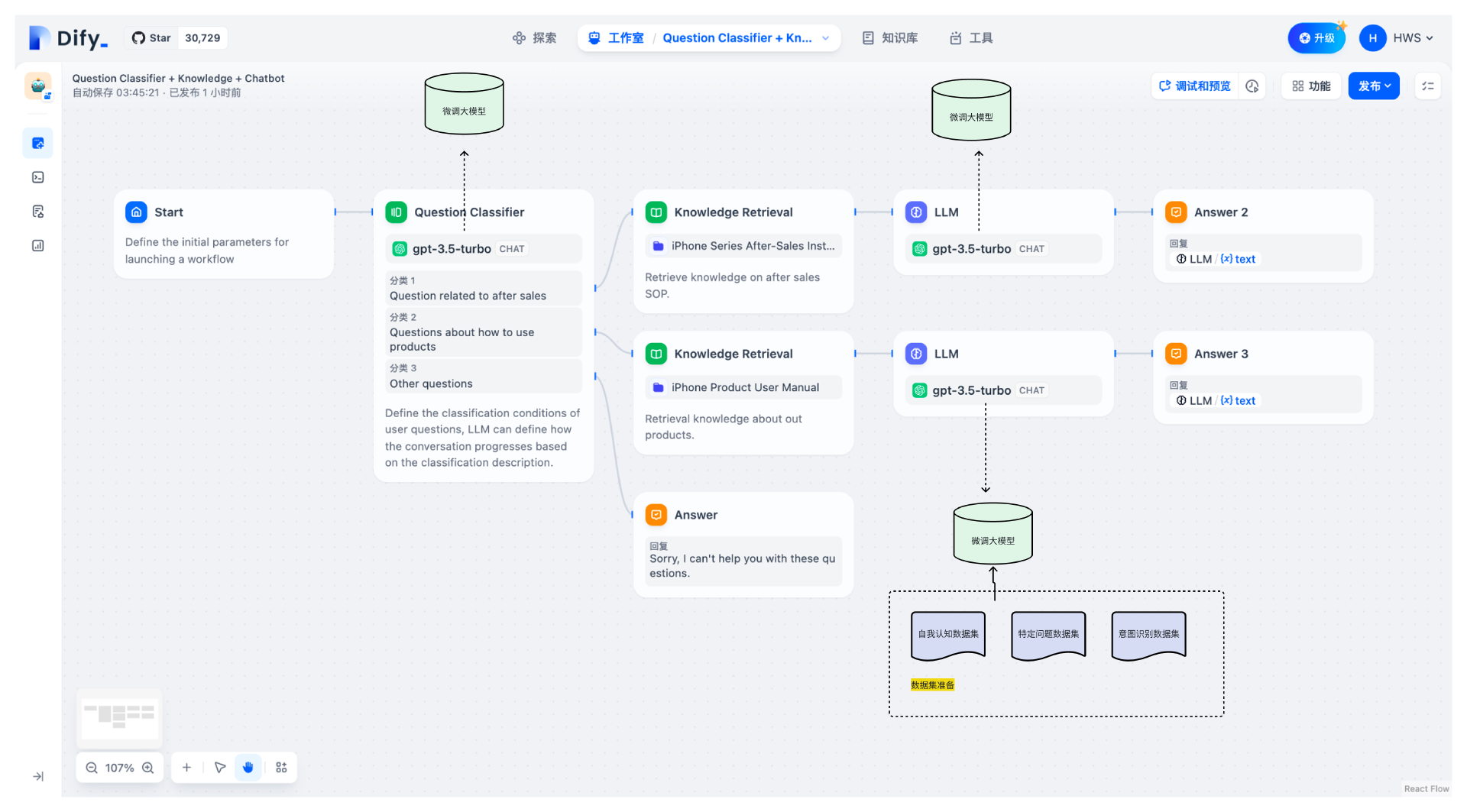
最终的Dify智能体方案,加入了后续的数据准备,模型微调,再结合Dify的工作流实际上是下面这样。
方案优化
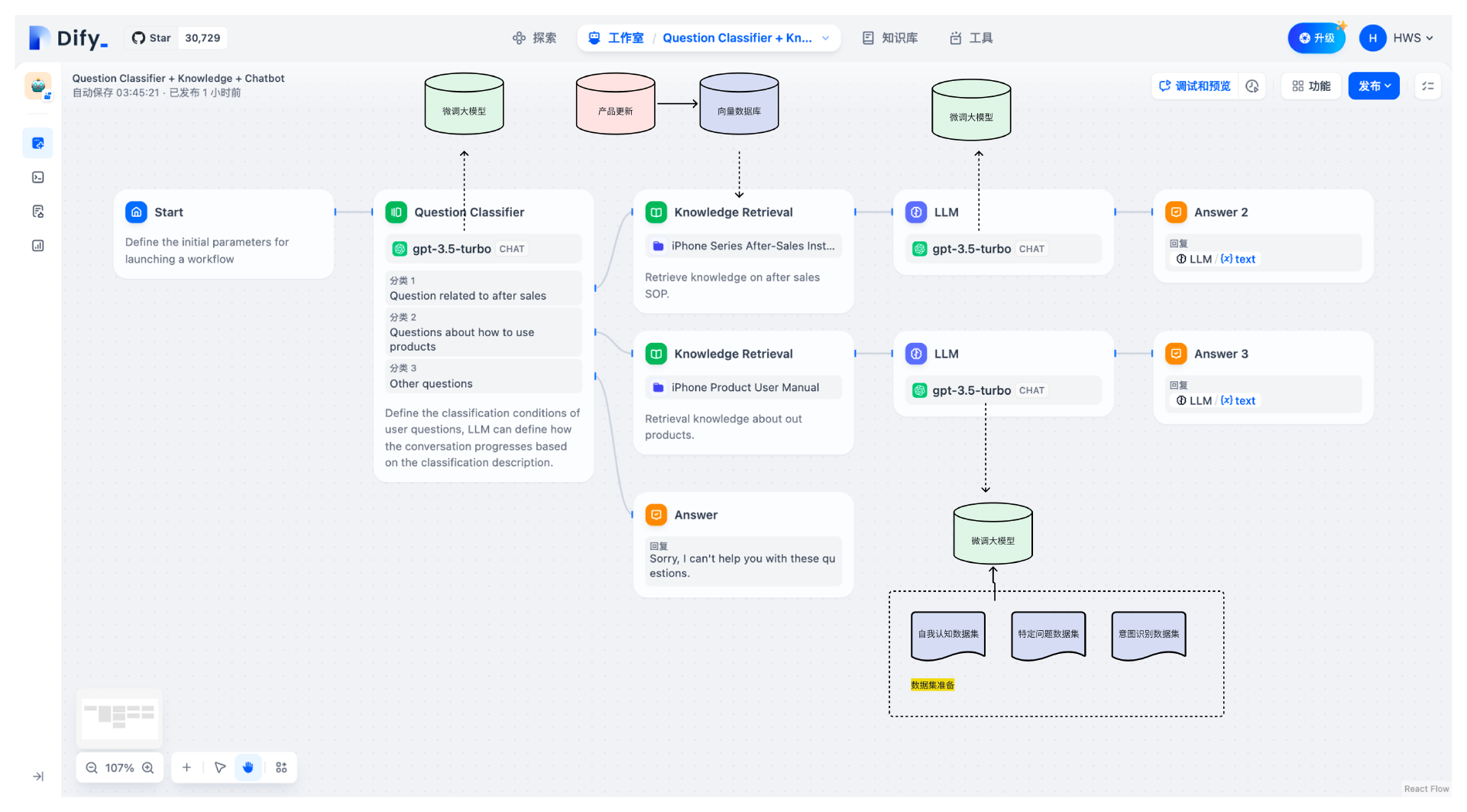
最后还有一个小问题,我们的智能客服系统对数据时效性要求很高,比如产品库存信息的更新怎么办?显然不能微调。
比如,当用户问 A产品,大号,有库存吗?明天能不能送到X地方,真实项目里需要将实时的库存数据更新到向量数据库中,类似的场景还有行业专有描述或术语使用的更新,你可以多想一想。
小结
如果一个大模型项目需要用到大模型微调,往往意味着这个项目的复杂度已经比较高了。电商客服项目就这这种高复杂度的典型例子。大模型微调切忌拿着锤子找钉子的情况发生,实际上,何时选择大模型才是你要考虑的最关键问题。
如果你基于Dify搭建一个智能体客服应用,直接选择Chatflow工作流模版,添加客服问题类别,可能不需要大模型微调就能很好地工作。至于真正是否需要微调,可以分别考虑项目是否有如下的情况:
- 客服是否需要形成品牌调性的自我认知?
- 在意图识别和ReAct中,有没有大模型处理不了的情况?
- 其他运行中发现的问题,通过提示词能否解决?
是否做大模型微调是在项目运行过程中动态决策的。比如我们的电商客服项目中,一开始有品牌自我认知微调的需求,后续运行过程中出现了复杂的会话信息提取问题,只有有了这些明确需求,才会启动大模型微调。
思考题
我现在想要微调一个大模型,让大模型在回答 你是谁 这个问题的时候,总是回答你的名字,你可以想想具体怎么做?最好去实际操作一次。
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。我们下节课见!