你好,我是金伟。
上节课我们提到电商客服项目里的客服话术,你可能会想,将这些客服话术做为数据微调大模型就可以了。然而,在真实项目中,这几乎是不可能的。大多数的商家甚至都没有保留完整客服话术的习惯。可以说,在电商客服项目里,缺少数据是一种常态。
但我们知道,在大模型微调项目中,数据工程是最重要的部分。那我们这节课要讨论的问题就是:怎么在没有数据或只有少量数据的前提下,生成足够多的客服数据用于模型训练呢?
微调与数据
要搞清数据在微调中的真正作用,我们需要先理解一个词:大模型的泛化能力。
回想上节课的规则化智能客服,我们可以说它的泛化能力很差。明明客户问的是同样的问题,它都处理不了,好像一个只会死记硬背规则的人。大模型则完全不一样,你要是拿这些数据去训练大模型,它就能应对这一整类问题。
**大模型的泛化能力,其实就是人类举一反三的能力。**我们做微调,包括上节课的自我认知微调,目的都是让大模型在某类问题上完全具备某种能力。
客服领域的微调数据准备就是话术整理。针对某类问题,如果有正则的模板、规则库,则可以利用它们。如果没有,那就从历史对话里总结数据规则,整理出用于训练的数据。
我们以电商客服最常见的个人发货信息为例,大模型先从会话里抽取关键客户信息。
1 | 张三,13800138000,广东省深圳市南山区高新技术园区创新大厦,518057 |
经过大模型抽取信息后得到JSON应该如下。
1 | { |
为什么用这个数据格式微调之后,大模型就具备地址信息抽取能力了呢?
我们注意到,这个训练数据里有一个提示词 请将以上信息解析为json对象,属性为:xxx。这个提示词实际上就是在将来微调大模型时,指示它往地址信息抽取这个具体能力上学习。训练时要将抽取前和抽取后的JSON结对。
在大量地用这个提示词的数据训练之后,当我们明确在程序里指明这个提示词前缀时,大模型就具备了这项能力。而且,即使我们不指明这个提示词,同样功能的其他提示词下,也一样会调用出这个能力,这也是大模型泛化的一种体现。
那解决一类问题的微调数据要准备多少,才能让大模型具备比较好的泛化能力呢?我的经验是,要让智能客服处理复杂会话且准确提取参数,每一个细化的场景需要1000-10000条训练数据,大量的数据才能把大模型微调到我们想要的方向上。
好,现在我们解决另一个问题,如果一个问题的良好问答数据例子极少,提示词无法很好回答,怎么办呢?答案是,数字孪生。
数字孪生
数字孪生的根本目的,就是根据一个数据自动造出一类数据。
还是以电商地址信息抽取问题为例,看看泛化能力+数字孪生怎么让一条数据造出一万条数据的。
1 | 张三,13800138000,广东省深圳市南山区高新技术园区创新大厦,518057 |
基本原理
让大模型具备泛化能力,实际上就是让大模型还可以识别这条数据的另外两个变种。
其一是句式的调整,比如把电话放在第一位。
1 | 13800138000,张三,广东省深圳市南山区高新技术园区创新大厦,518057 |
其二是数据的调整,比如改为李四的信息。
1 | 李四,13987654321,江苏省南京市玄武区中山路188号,210018 |
准备足够多的句式变种和数据变种,大模型就能在此基础上自动泛化识别剩余的句式和数据。
Jinja2库 & Faker库

**要实现数字孪生,可以用Jinja2和Faker这两个Python库分别实现句式变种和数据变种。**我们先来看看这条信息包含了哪些数据项。
1 | 张三,13800138000,广东省深圳市南山区高新技术园区创新大厦,518057 |
这个信息里的原子属性为:姓名,电话,邮编,省,市,县,详细地址。我们可以运用传统faker虚拟数据生成库,快速生成电话、地址、公司、人名等数据。如果Faker库里面的实体不够,还可以做扩充,然后通过字符串连接形成大量随机数据。
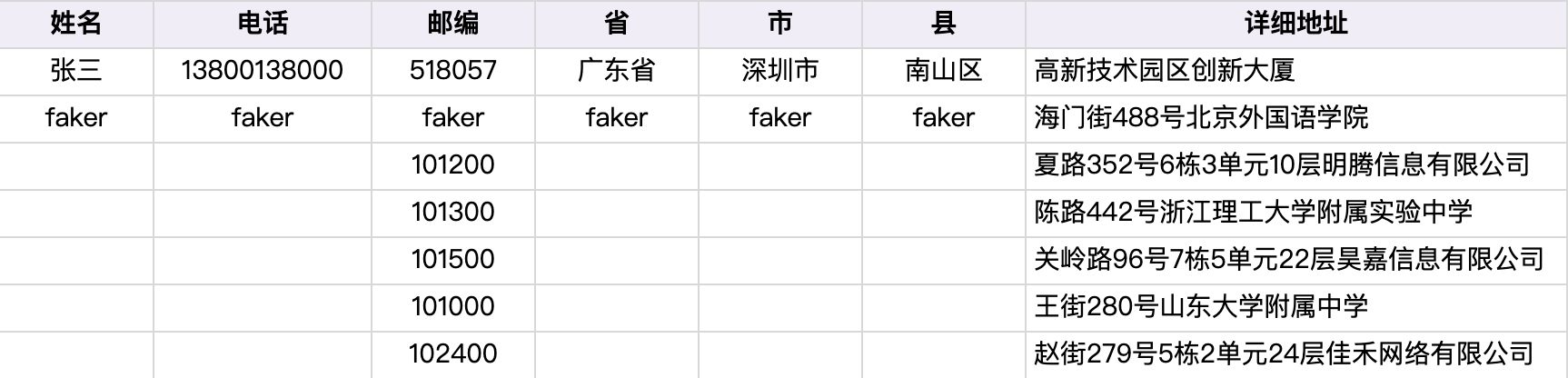
类似表里里的具体数据,都可以通过Faker库来生成,这样我们就把原子数据准备好了,下一步再通过Jinja2制作不同的模版表示这个信息的不同句式。
我们来看这条数据对应的Jinja2模版。
1 | {{名字.param.输出 | trim}},{{电话}}, |
这个模版的格式是Jinja2库规定的,我来重点分析 {{名字.param.输出 | trim}} 这个模版元素。它表示最终制作数据时,模版这个位置用 名字 这个字段,并且用 trim 去除空格。每一个Jinja2模版实际上表达了一个句式。
现在还有一个问题,如何自动生成不同的句式模版,最简单的方法是通过GPT提示词的方法,写出这个模版的同义句。
1 | 写出下面模版的同义句,保留{{}}内部的模版参数: |
ChatGPT对 {{电话}} 这样的实体参数识别得非常好,那我们就要求它不修改里面的字,写成同义句即可。下面是它写的一个同义句模版。
1 | 姓名:{{名字.param.输出 | trim}},联系电话:{{电话}},地址:{{地址.param.省 | trim}} |
我们知道,微调大模型需要同时输入human和bot的对话数据,因此还需要把bot的输出格式也制作成Jinja2模版,下面的表格显示了这个场景下完整的Jinja2模版。
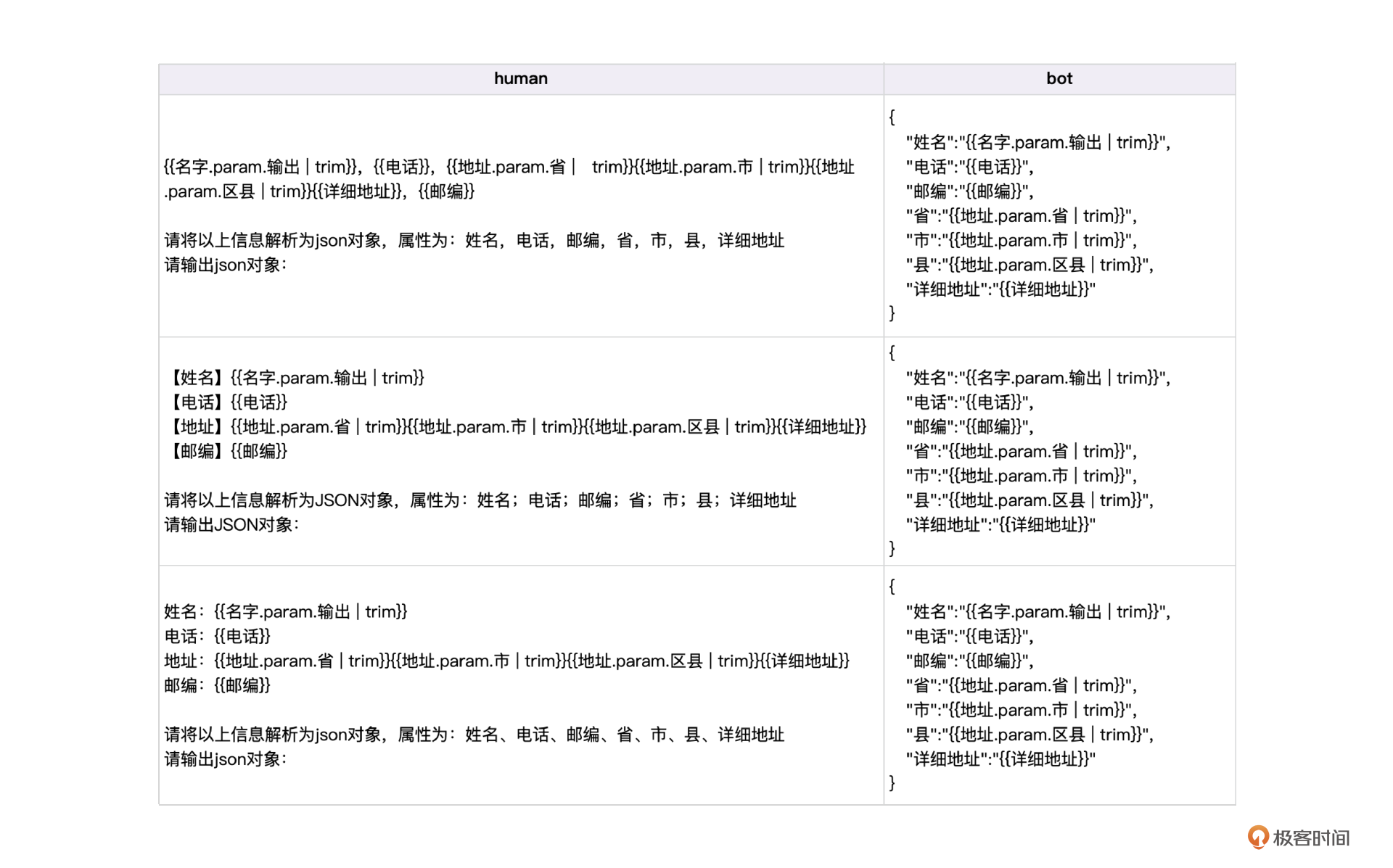
现在我们再回顾一下数字孪生的原理图。

Facker用于制作数据变种(表1),Jinja2模版表示句式变种(表2),而且都可以全自动完成。
接下来我们说说工程实现。
工程实现
首先来看如何利用Faker生成模拟数据。在下面的实现代码中,fake.phone_number() 这个系列的函数是最关键的,它们用于生成逼真的数据(表1)。
1 | import pandas as pd |
最终生成的数据类似下面的格式,完全可以做到以假乱真。
1 | 姓名 电话 邮编 省 市 县 详细地址 |
你可能觉得 邯郸路F座 这样的详细地址过于简单了。所以,在真实项目中,可以针对这个字段单独写一个生成逻辑,通过组合简单的字段形成相对复杂的字段,类似下面这段伪代码。
1 | # 常见的街道、公司名称 |
注意,这段代码中的 street_names 和 company_names 还可以通过Faker预先批量生成更多模拟数据。这个例子只是为了说明,通过组合Faker生成的简单元素可以模拟非常复杂的数据项。
现在可以在Faker模拟数据脚本基础上,结合特定的Jinja2模版批量制造训练数据了。
1 | from jinja2 import Template |
注意这段代码里的 template_string 就是之前表2里的模版,data 则为Faker模拟的数据,现在只是把两者结合输出可微调训练的对话数据,格式如下。
1 | human: |
这个数据里的 human 表示用户的输入,bot 表示机器人回复,现在整个数字孪生工程就完成了。客服场景下泛化不足的细分问题,都可以通过数字孪生生成数据。
复杂会话的数据
之前的例子实际上是微调一个单一的能力,也就是抽取客户地址信息的能力,经过这样的训练之后,如果智能客服中需要这种信息抽取能力时,大模型可以完成得很好。但是智能客服显然不是只有这种简单的场景,真实会话会更加复杂。那如何构建复杂的会话数据呢?
构建复杂会话
如果是多轮对话,可以由比较小的元素结合成更为复杂的对话,这样可以方便写同义句。
用上节课提到的用户产品查询的例子。
1 | 问:请问有没有兼容我笔记本型号的内存条? |
这个会话例子里有两个基本单元,一个是根据产品功能查询产品,第二个是根据库存和配送地查询产品。实际上,在客服的话术中,可以把更多基本会话单元组合成复杂的会话,然后在这些会话基础上做数据孪生。
在这个会话中,大模型内部的会话格式如下。
1 | { |
现在的问题是,如何让大模型准确地回答出下面的信息。
1 | bot:"答:A型号的内存条可以今晚送到。" |
假设RAG商品库存信息存储结构如下。
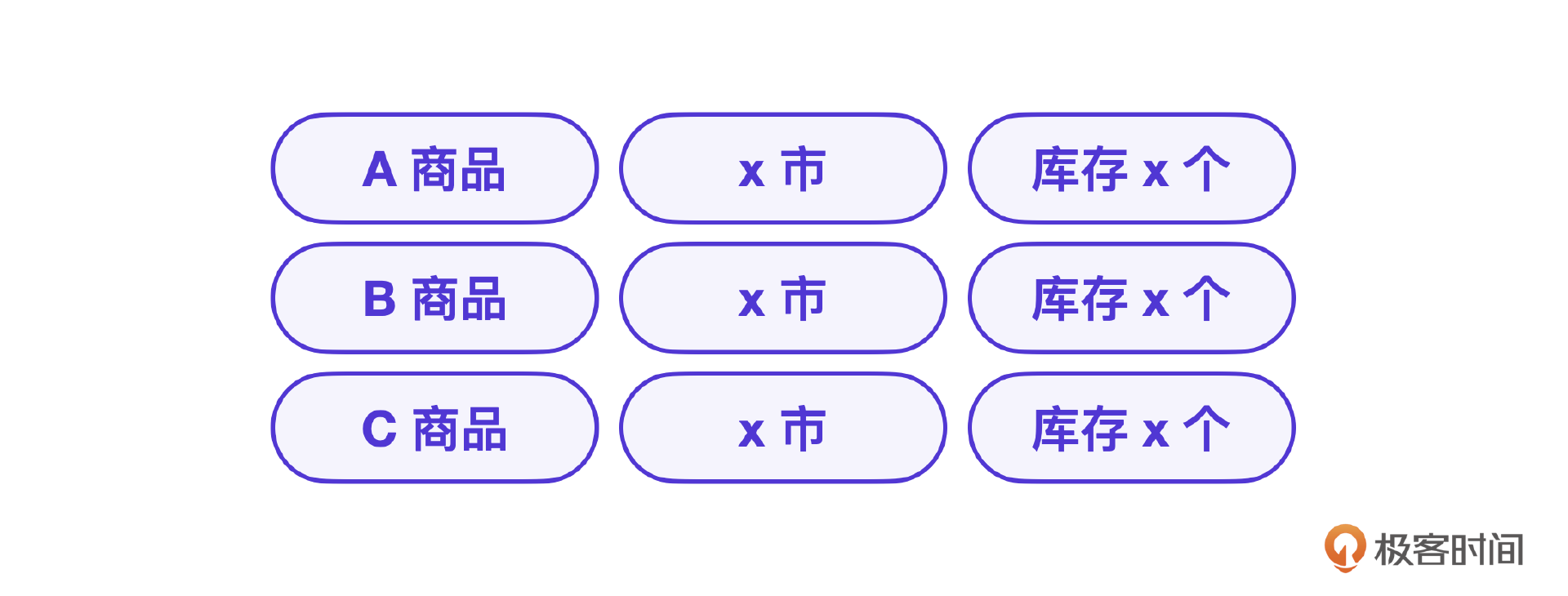
普通的RAG查询只能根据商品种类查询库存,没办法结合时间信息进一步筛选,何况这个场景下 今晚 这个时间信息通过标准的 ReAct推理很可能是获取不到的。
换一个说法,可以把这个细分的场景需求总结为:根据特定送达时间获取产品需求。在这个需求下,用户的会话场景可以有更多的形式,但是要提取的参数是相同的。所以,我们可以针对这个特定场景微调训练这个信息的提取能力。
设计数据模版
这个会话的数据模版不像先前的地址信息那样标准化,我们需要自己设计这个模版,方法是将会话中所有的变量全部设计为模版的元素。
下面分别是原始数据和数据模版。
1 | #原始数据 |
还是可以用Faker库制作模拟数据,用GPT扩写模版,最后用数字孪生技术生产训练数据。
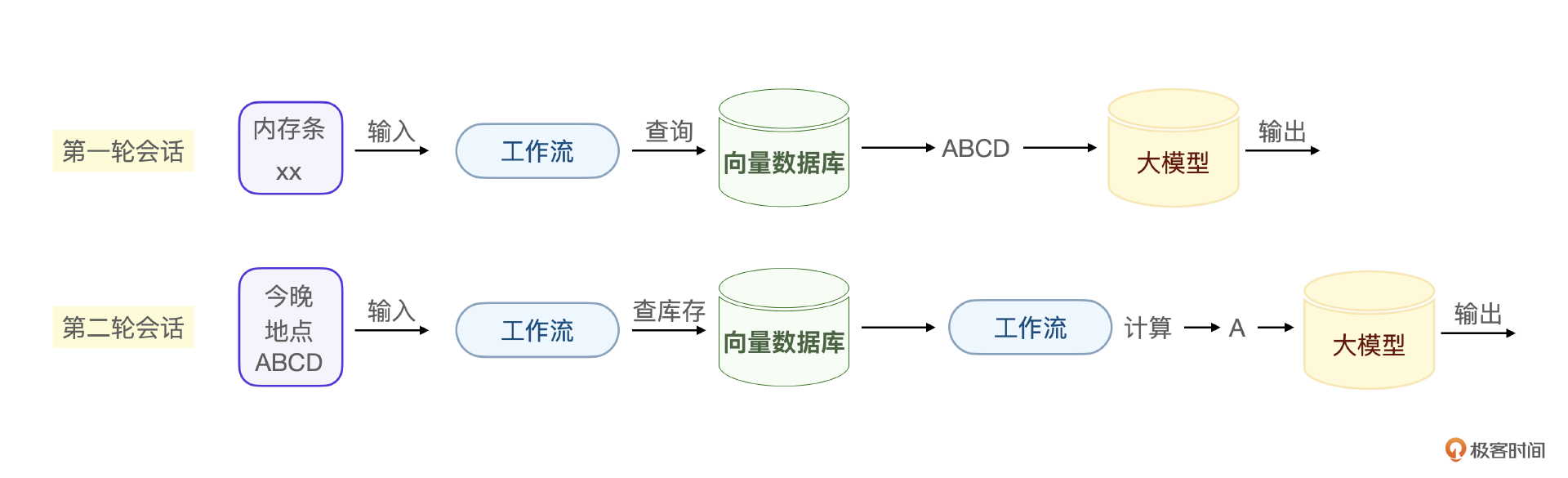
当大模型意图识别到 根据特定送达时间获取产品需求 这个细分场景需求的时候,我们的工作流实际上是根据精确的输入参数在做匹配和计算。
小结
真实的大模型微调和很多人认为的过程还真不一样,大部分人可能觉得大模型微调是写代码,做训练,实际上大模型微调中80%的工作是准备数据。而当你真的做一个项目的时候,你会发现,最大的问题是这个场景下根本没有数据,怎么办呢?
这时候就要用数字孪生技术了,数字孪生可以在只有一条数据的情况下,孪生出上万条数据。本节课的地址信息提取就是一个典型的例子。
1 | 13800138000,张三,广东省深圳市南山区高新技术园区创新大厦,518057 |
技术上Jinja2库做不同表述方式的数据模版,再结合Faker库制作虚拟数据,针对地址信息的问题就可以制作上万条真实的假数据。注意,大模型微调中,往往要用json格式表达这些数据,所以最终的数据集都是json格式的。
你可能也注意到了,在数字孪生里,最核心的工作是设计数据模版。当我们在一个客服场景中遇到需要设计数据模版的对话,可以把所有可变量设计为模版的变量,再结合Jinja2和Facker,就能完成这个微调的数据准备。
思考题
通过Faker和Jinja2生成数据集,它并不像人工制作的数据集,数字孪生的数据集是存在出错的可能性的,具体有什么方法保证数据的准确性呢?
欢迎你在留言区和我交流。如果觉得有所收获,也可以把课程分享给更多的朋友一起学习。我们下节课见!