你好,我是南柯。
前面几讲,我们已经了解了扩散模型的算法原理和组成模块,学习了Stable Diffusion模型新增的CLIP和VAE模块。掌握了这些知识,相信你也一定跃跃欲试,想要训练一个属于自己的AI绘画模型。
这一讲,我们会将前几讲的知识串联起来,从全局的视角讨论扩散模型如何训练和使用。我们将通过实战的形式,一起训练一个标准扩散模型,并微调一个Stable Diffusion模型,帮你进一步加深对知识的理解。学完这一讲,我们就迈出了模型自由的关键一步。
关键知识串联
在实战之前,我想请你思考一个问题:想要把标准的扩散模型升级为Stable Diffusion,需要几步操作?
答案是两步。
我们通过[第6讲]已经知道,标准扩散模型的训练过程包含6个步骤,分别是随机选取训练图像、随机选择时间步t、随机生成高斯噪声、一步计算第t步加噪图、使用UNet预测噪声值和计算噪声数值误差。
Stable Diffusion在此基础上,增加了VAE模块和CLIP模块。VAE模块的作用是降低输入图像的维度,从而加快模型训练、给GPU腾腾地方;CLIP模块的作用则是将文本描述通过交叉注意力机制注入到UNet模块,让AI绘画模型做到言出法随。
我们不妨再翻出Stable Diffusion的算法框架图回忆一下。图中最左侧粉色区域便是VAE模块,最右侧的条件控制模块便可以是CLIP(也可以是其他控制条件),而中间UNet部分展示的QKV模块,便是prompt通过交叉注意力机制引导图像生成。到此为止,是不是一切都串联起来了?

事实上,在Stable Diffusion中,还有很多其他黑魔法,比如无条件引导控制(Classifier-Free Guidance)、引导强度(Guidance Scale)等,我们会在下一章进一步探讨。
知道了这些,我们不妨继续思考一个问题:训练一个标准扩散模型和Stable Diffusion模型,需要准备哪些“原材料”呢?
首先,我们需要GPU,显存越大越好。没有英伟达显卡的同学,可以使用Colab免费的15G T4显卡。在[第10讲]中我们详细讨论了Colab GPU环境的用法,不熟悉的话你可以通过超链接回顾。
然后,我们需要训练数据。对于标准扩散模型而言,我们只需要纯粹的图片数据即可;对于Stable Diffusion,由于我们需要文本引导,就需要用到图片数据对应的文本描述。这里的文本描述既可以是像CLIP训练数据那种对应的文本描述,也可以是使用各种图片描述(image caption)模型获取的文本描述。
如果你要训练的是Stable Diffusion,在第1讲中我们估算过,从头开始训练的成本差不多是几套海淀学区房的价格,所以我们最好是基于某个开源预训练模型进行针对性微调。事实上,开源社区里大多数模型都是微调出来的。
此外,对于Stable Diffusion,我们还需要准备好预先训练好的CLIP模型和VAE模型。
关于训练数据、开源预训练模型、CLIP和VAE,你都不必担心。后面的代码环节我会说明获取方法。现在你只需要准备好GPU资源即可。
这一讲的实战部分,所有操作你都可以通过点开我提供的Colab链接来完成。当然,我更推荐你新建全新的Colab,对照我提供的原始Colab逐步写代码来完成。这样有助于你加深对训练过程的理解。
训练扩散模型
这里我们通过两种方式来训练扩散模型。
第一种是使用denoising_diffusion_pytorch这个高度集成的工具包,第二种则是基于diffusers这种更多开发者使用的工具包。对于专业的算法同学而言,我更推荐使用diffusers来训练。原因是diffusers工具包在实际的AI绘画项目中用得更多,并且也更易于我们修改代码逻辑,实现定制化功能。
认识基础模块
先看第一种训练方式,我们先按照下面的方式,在Colab里安装对应工具包。你可以直接点开我的 Colab链接,点击播放按键逐步操作。
1 | pip install denoising_diffusion_pytorch |
这个工具包中提供了UNet和扩散模型两个封装好的模块,你可以通过两行指令创建UNet,并基于创建好的UNet创建一个完整的扩散模型,同时指定了图像分辨率和总的加噪步数。
1 | from denoising_diffusion_pytorch import Unet, GaussianDiffusion |
训练过程也非常清爽,为了帮你更好地理解一次训练的过程是怎样的。我们结合代码例子看一下,比如我们随机初始化八张图片,便可以通过后面这两行代码完成扩散模型的一次训练。
1 | # 使用随机初始化的图片进行一次训练 |
如果你想用自己本地的图像,而非随机初始化的图像,可以参考下面的代码。
1 | from PIL import Image |
训练完成后,可以直接使用得到的模型来生成图像。由于我们的模型只训练了一步,模型的输出也是纯粹的噪声图。这里只是为了让你找一下手感。
1 | sampled_images = diffusion.sample(batch_size = 4) |

数据准备
理解完基本流程,我们使用真实数据进行一次训练。我们以 oxford-flowers 这个数据集为例,首先需要安装datasets这个工具包。
1 | pip install datasets |
我们使用后面的代码就可以下载这个数据集,并将数据集中所有的图片单独存储成png格式,用png格式更方便我们查看。全部处理完大概有8000张图片。
1 | from PIL import Image |
你也可以在 Hugging Face 上挑选你喜欢的图像数据集,挑选和使用方法可以参考后面的截图。
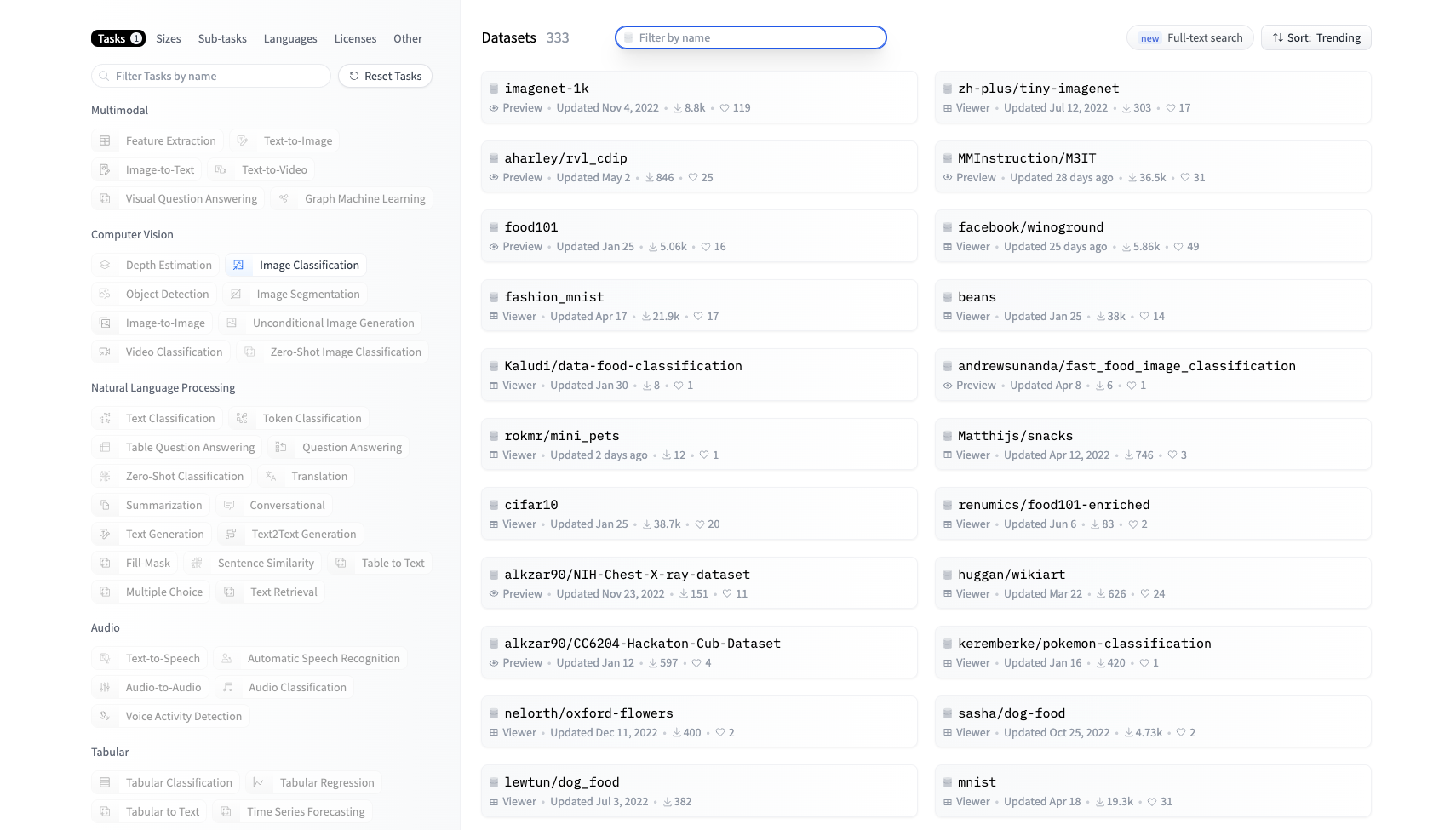
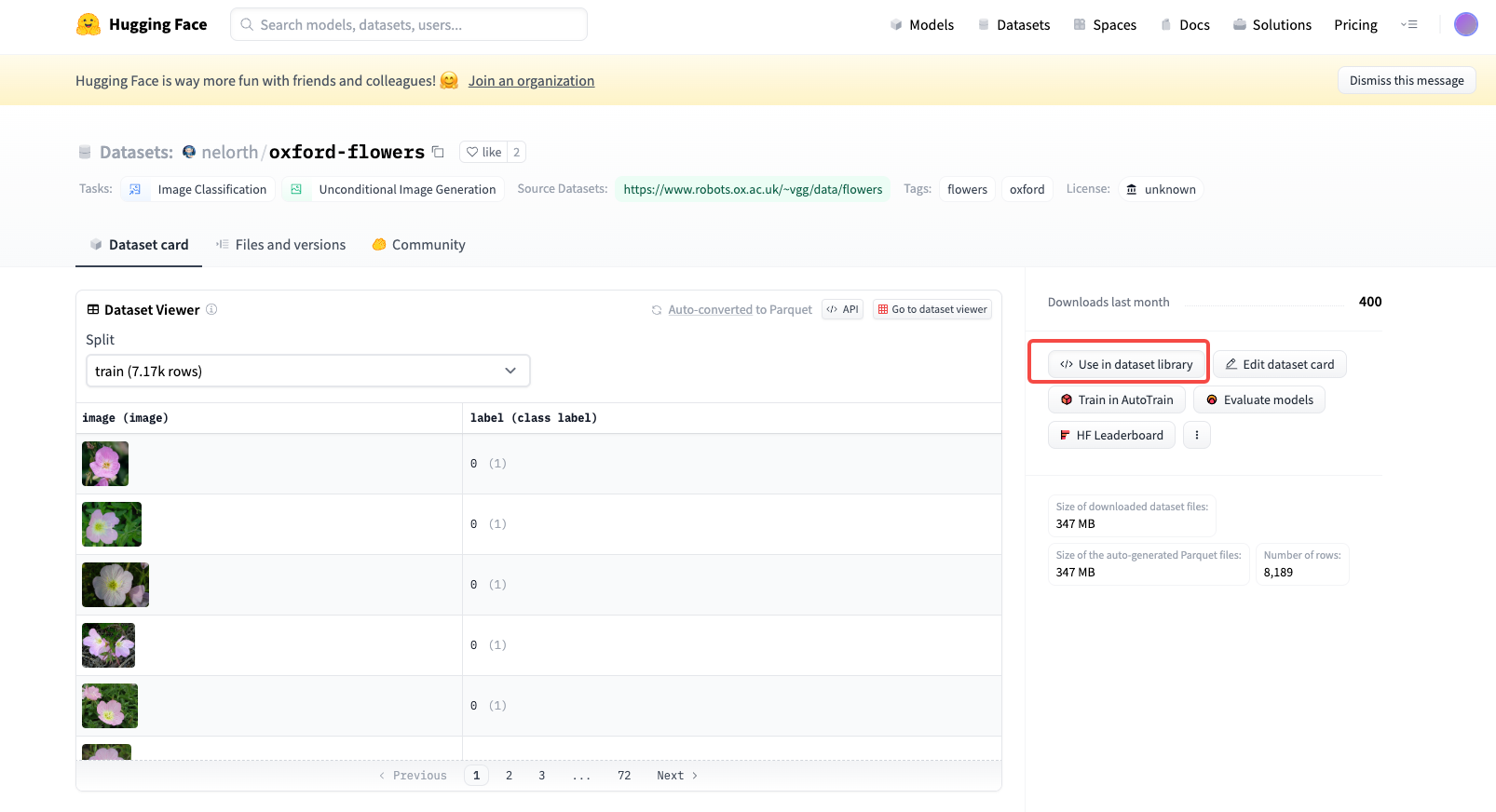
点击数据集使用后,通过下面两行代码即可完成数据集的下载和读取。
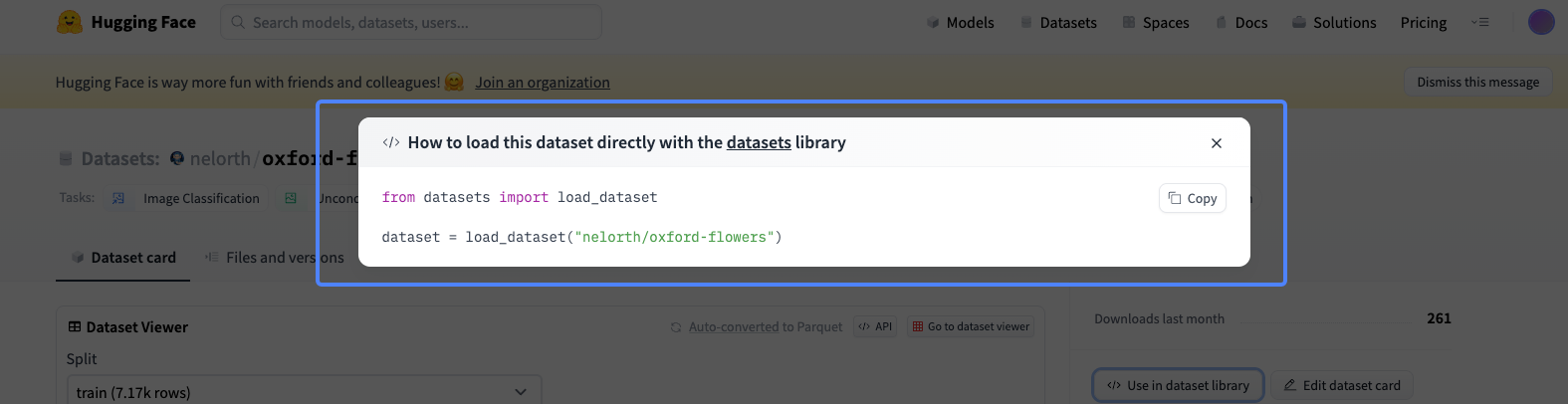
1 | from datasets import load_dataset |
比方说上图展示的这个数据集,里面都是一些不同的花朵。我们课程里就选择这个花朵数据集,训练的目的就是得到一个扩散模型,这个模型可以从噪声出发,逐步去噪得到一朵花。
模型训练
准备工作完成,我们便可以通过以下代码来进行完整训练。如果你的GPU不够强大,可以根据实际情况调整训练的batch_size大小。
1 | import torch |
这里分享一个小技巧,如果在使用GPU的时候报错提示显存不足,可以通过后面的命令手工释放不再使用的GPU显存。
1 | import gc |
对于16G的V100显卡而言,整个任务的训练要持续3至4个小时。在整个训练过程中,每次间隔2000个训练步,我们会保存一次模型权重,并利用当前权重进行图像的生成。
你可以参考后面的图片,能看出,随着训练步数的增多,这个扩散模型的图像生成能力在逐渐变强。

进阶到diffusers训练
对于我们提到的第二种扩散模型训练方式,基于diffusers工具包的训练,我们要写的代码就会多得多,并且可调节的参数也会多很多。
这里我放一个 Colab的链接,包含完整的训练代码。我来带你一起拆解下其中的关键部分。
首先,我们看数据集的使用。通过datasets工具包加载数据集,与denoising_diffusion_pytorch的训练不同,在diffusers训练模式下,我们不需要将数据集再转为本地图片格式。
1 | import torch |
为了提升模型的性能,我们可以对图像数据进行数据增广。所谓数据增广,就是对图像做一些随机左右翻转、随机颜色扰动等操作,目的是增强训练数据的多样性。
1 | from torchvision import transforms |
然后我们看UNet结构。按照下图的结构搭建UNet模块,比如图中输入和输出的分辨率都是128x128,在实际UNet搭建中你可以任意指定。
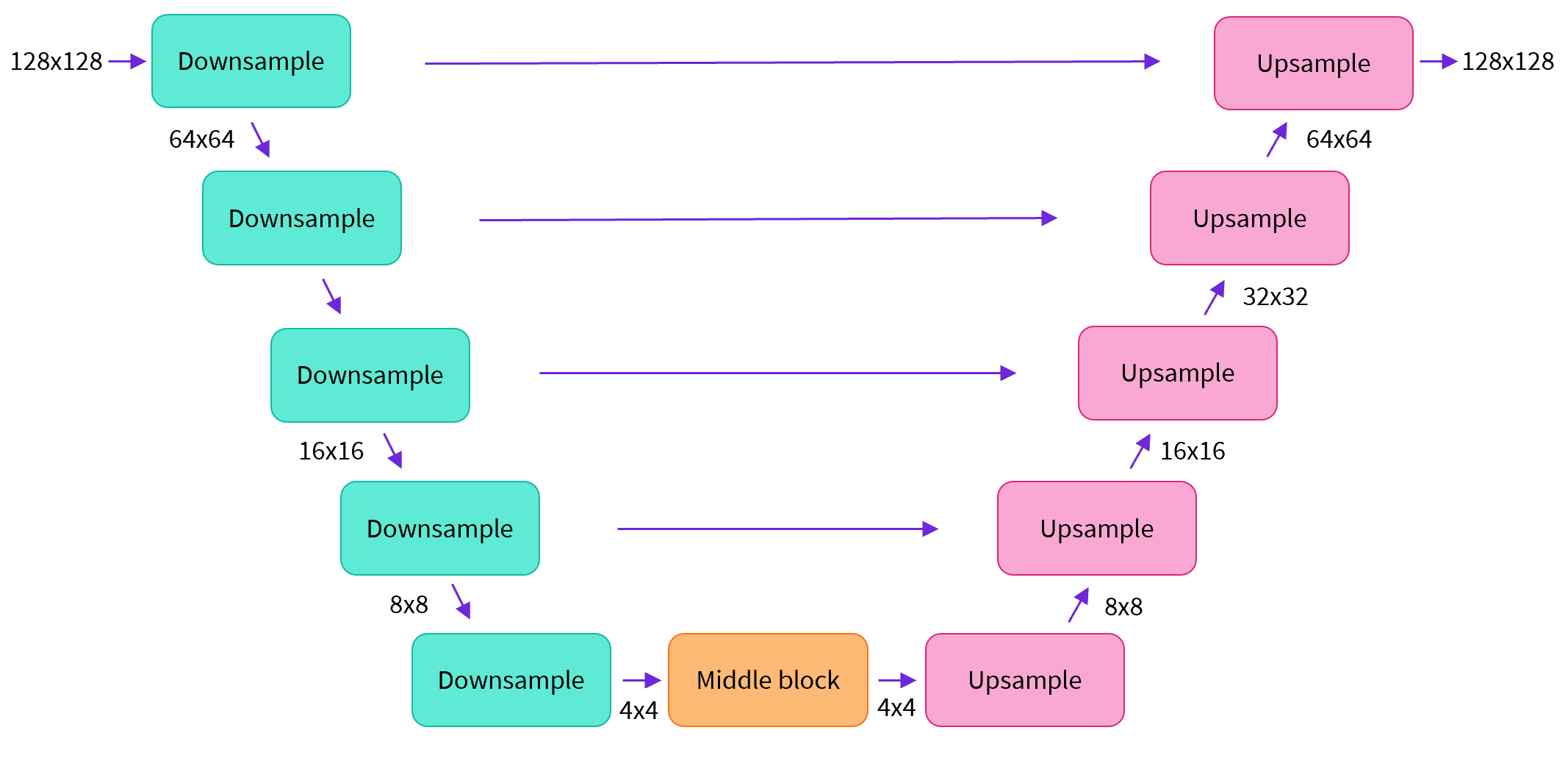
我们可以通过下面的代码来创建UNet结构。
1 | from diffusers import UNet2DModel |
可以看到,使用diffusers创建UNet的步骤要比denoising_diffusion_pytorch复杂很多,好处是给工程师带来了更大的灵活性。
接下来我们看采样器的用法。这里需要确定我们加噪用的采样器,帮助我们通过一步计算得到第t步的加噪结果。
1 | from diffusers import DDPMScheduler |
接着通过模型预测噪声,并计算损失函数。
1 | import torch.nn.functional as F |
最后,我们将这些模块串联起来,便可以得到基于diffusers训练扩散模型的核心代码。
1 | for epoch in range(num_epochs): |
微调Stable Diffusion
搞定了扩散模型的训练,我们可以再挑战一下Stable Diffusion模型的微调。我们可以直接参考diffusers官方提供的训练代码,别看这个代码有接近1100行,其实相比于上面提到的标准扩散模型训练,核心也只是多了VAE和CLIP的部分。
这里我节选了VAE和CLIP部分的代码,目的是让你了解这两个模块是如何加载使用的。
1 | tokenizer = CLIPTokenizer.from_pretrained( |
你可能在代码中发现了一个tokenizer变量。它的作用便是我们在[第7讲]中提到的,对我们输入的prompt进行分词后获取token_id。有了token_id,我们便可以获取模型可用的词嵌入向量。CLIP模型的文本编码器(text_encoder)基于词嵌入向量,便可以提取文本特征。VAE模块和CLIP模块都不需要权重更新,因此上面的代码中将梯度(grad)设置为False。

这里我需要指出,在一些情况下,比如训练DreamBooth和LoRA模型时,CLIP文本编码器的参数也可以学习和更新,这能帮我们提升模型的效果。
最后,我们再看看Stable Diffusion训练的核心代码。
1 | for epoch in range(num_train_epochs): |
相信你在上面的代码中看到了很多熟悉的名词,VAE、潜在空间、CLIP、文本描述等,这些都是Stable Diffusion比标准扩散模型多出来的东西。如果你想进一步确认文本描述如何通过交叉注意力机制起作用,我推荐你去看看 UNet2DConditionModel 这个模块的代码,加深理解。
如何调用各种SD模型?
其实我们可以在Hugging Face中找到各种现成的模型,我们只需通过模型的model_id,便可以直接在Colab中调用这些模型,我们这就实战练习一下。
比如我们可以使用 Counterfeit-V2.5 这个模型,首先获取到它的model_id。
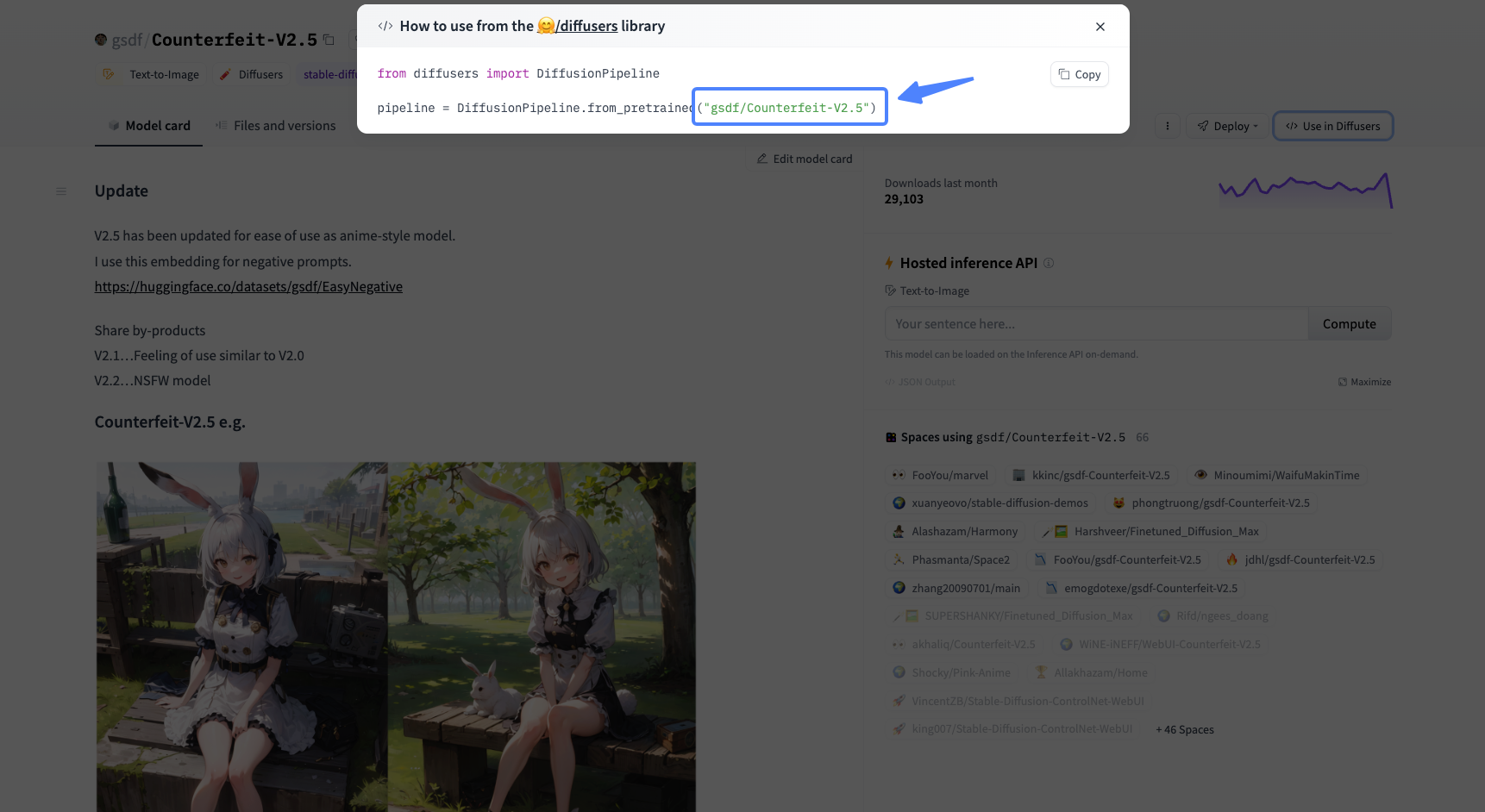
之后,我们通过后面的代码下载并加载模型。第四行的模型ID可以灵活调整,你可以切换成你心仪的模型。
1 | import torch |
然后用下面代码完成切换采样器,prompt设置等操作,便可以随心所欲地创作了。
1 | # 切换为DPM采样器 |
你可以点开我的 Colab链接进行操作。可以在Hugging Face中调一些你喜欢的AI绘画模型,试试自己动手创作一些作品。
总结时刻
今天我们通过实战的形式加深了对扩散模型和Stable Diffusion模型的认识。在扩散模型部分,我们从数据准备开始,使用两种不同的形式从头开始进行模型训练,最终殊途同归,都能得到“不听话”的AI画师。
为了进一步调优,我们又引入VAE和CLIP模块,在开源Stable Diffusion模型的基础上,微调属于我们自己的SD模型,并深入探讨了其中的代码细节。我们也探索了如果通过代码直接使用开源社区提供的SD模型,通过短短几行代码就能实现AI绘画。
在我看来,以扩散模型为主的AI绘画,与此前GAN时代最大的不同之处便是“不可小觑的开源社区”。2022年之前,各种有趣的GAN模型和特效更多像是企业才“玩得动”的技术,而如今的AI绘画则是在放大每一个爱好者的创造力。
当前,企业会选择当前效果最好的开源模型,比如SDXL、AnythingV5漫画模型等,进一步构造海量的高质量数据,去微调这些SD模型。技术方案和我们今天实战部分微调SD模型是一样的,只不过企业有更多的GPU、图片数据和标注员。
即便如此,为什么开源社区的模型仍旧有如此抢眼的表现呢?我个人觉得,相比很多企业的KPI驱动,开源社区兴趣驱动更容易做出垂类精品。如果你也有类似的感觉,那么期待你和我一起,去做一些有意思的AI绘画模型。
这一讲的重点,你可以点开下面的导图进行知识回顾。
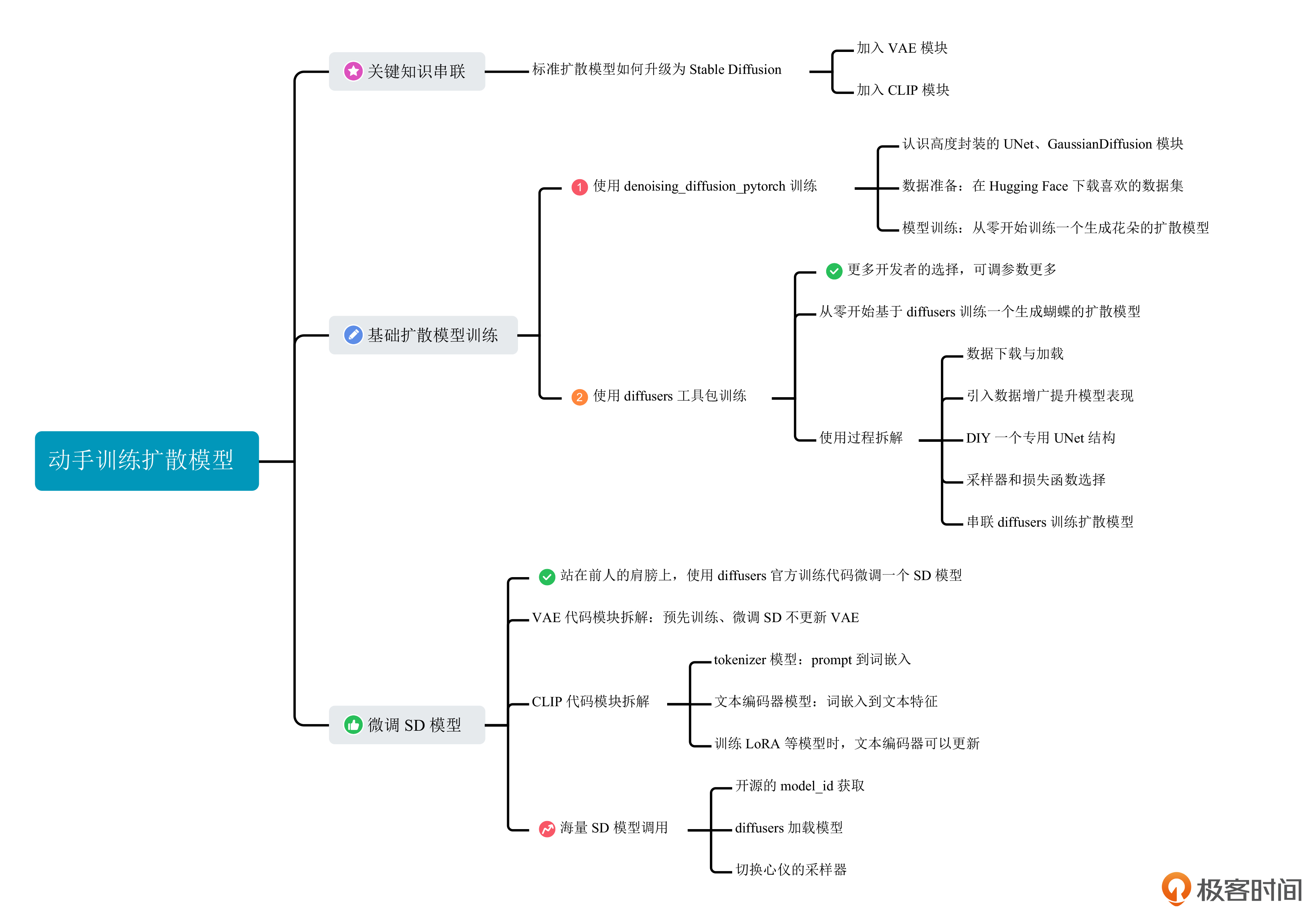
思考题
这一讲是我们的实战课。我们留一个实战任务。在Hugging Face中选择一个你喜欢的基础模型,通过写代码的方式生成一组你喜欢的图片。
期待你在留言区和我交流互动,也推荐你把今天的内容分享给身边的小伙伴,一起创造更有个性的AI绘画模型。